

NexGen Cloud has added a framework that enables application developers to more easily build artificial intelligence (AI) applications on top of its cloud service.
Cory Hawkvelt, CTO and chief product officer for NexGen Cloud, said Hyperstack AI Studio provides organizations that leverage the company’s graphics processing unit (GPU) services with a set of tools for also building and deploying applications. The overall goal is to reduce the level of friction that organizations would otherwise encounter by having to integrate a separate set of third-party tools.
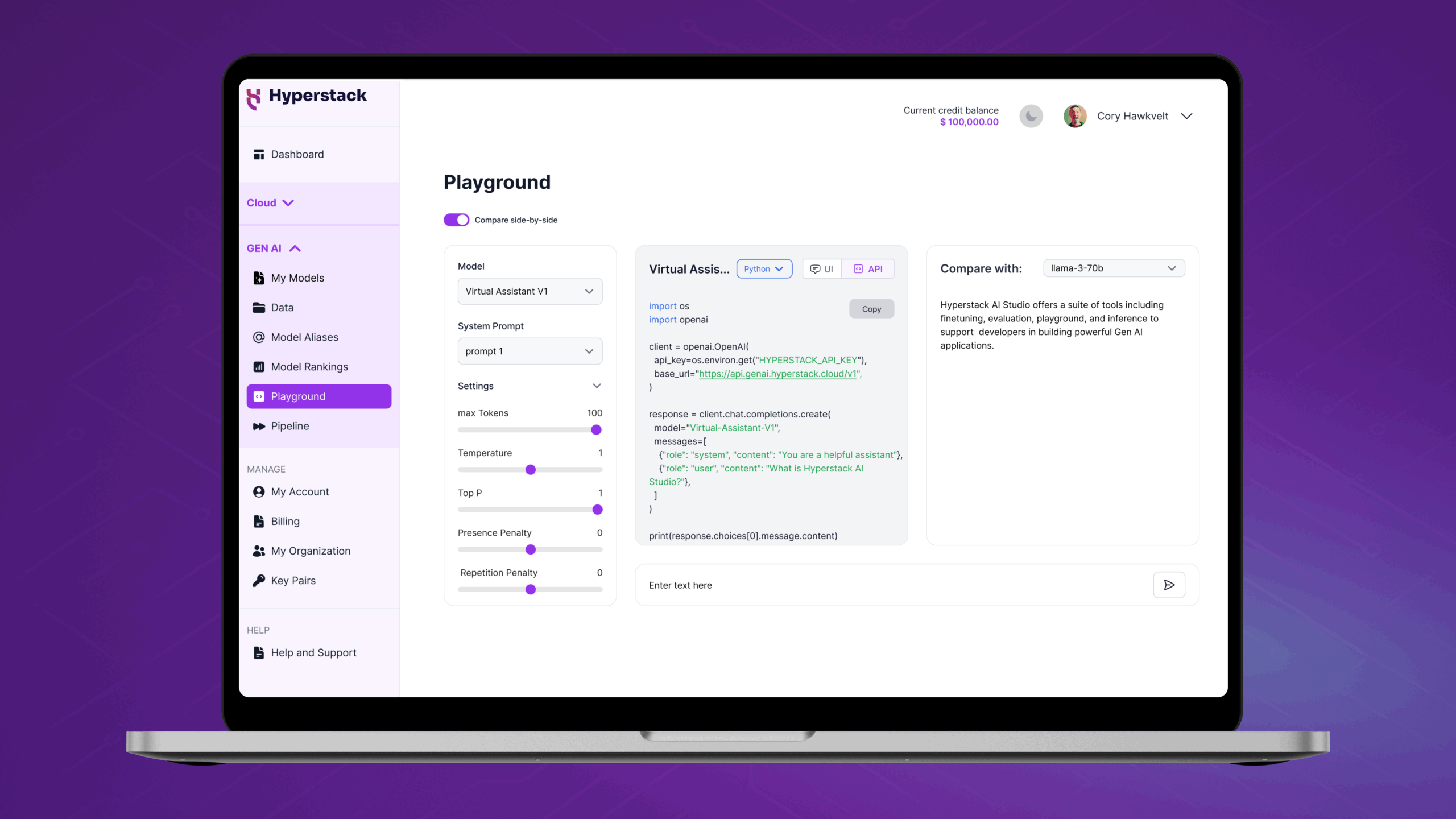
Priced based on usage, Hyperstack AI Studio supports open-source models like Llama and Mistral. Applications can be served via private API endpoints, eliminating the need to depend on third-party proprietary application programming interfaces (APIs). It also includes built-in tools for dataset management, model fine-tuning, performance evaluation and prompt testing.
Via a single unified interface, application developers can prototype applications in the model playground, compare model variants, and deploy private endpoints, with guardrails to be made available next.
The Hyperstack cloud service is based on a serverless computing framework that was originally developed for cryptocurrency applications. Alternatively, IT teams can now also opt for dedicated GPUs that are made available via a single-tenant private cloud to meet compliance and data sovereignty requirements. Regardless of approach, the Hyperstack cloud service supports the OpenAI-defined APIs for running AI inference workloads on cloud infrastructure.
It’s not clear how many organizations are adopting cloud services to build and deploy AI applications, but the Hyperstack service was built from the ground up for GPUs versus relying on, for example, an instance of OpenStack that was originally designed for virtual machines running on CPU, noted Hawkvelt. As a result, Hyperstack consumes GPU resources more efficiently than other cloud services to provide a simple cost-per-GPU pricing model on a per hour basis versus requiring customers to commit to extended contracts based on that amount of infrastructure consumed, he added.
There is already no shortage of options for accessing GPUs in the cloud. The challenge these days is rightsizing the class of GPUs required to build and deploy AI application workloads. There is a natural tendency for data science teams to always want the latest and greatest GPUs, but many AI workloads can be built and deployed using classes of GPUs that cost much less.
Hopefully, as GPUs and other classes of AI accelerators become more widely available, the overall pace of AI application development will increase. Many organizations today are limiting the number of AI applications that are willing to deploy in production environments simply because costs are too high. However, as the history of IT has always shown, the cost of deploying software generally declines as infrastructure becomes cheaper and the tools and applications that are deployed consume resources more efficiently.
In the meantime, however, the more advanced the IT platforms relied on to build and deploy AI applications become, the more likely it is that a lot more projects in the months ahead will be moving beyond the proof-of-concept stage.