
Our initial setup was a robust on-premises architecture designed to handle various data processing needs. However, it presented significant challenges that impeded efficiency and growth.
On-Premises Data Architecture
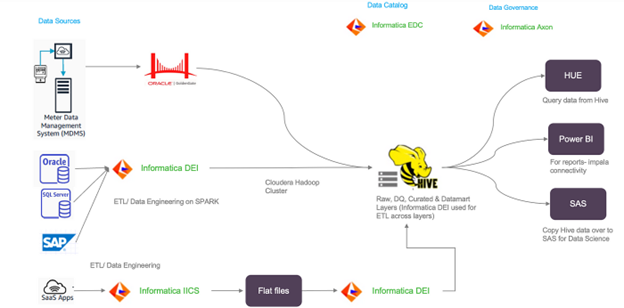
“On-Premises Data Architecture: A comprehensive view of our existing data infrastructure before migrating to the cloud”
Key Components
Data Sources:
- Meter Data Management System (MDMS) integrated with Oracle GoldenGate for replication
- Databases such as Oracle, SǪL Server and SAP for various data requirements
- SaaS applications contributing to the data pool
ETL/Data Engineering:
- Informatica DEI and Informatica IICS for ETL processes and data engineering on Spark
Data Catalog and Governance:
- Informatica EDC for data cataloging and Informatica Axon for data governance.
Data Consumption:
- Hive, HUE, Power BI and SAS for data querying, analytics and reporting.
Challenges Faced During On-Premises Setup
Despite its comprehensive nature, our on-premises infrastructure faced numerous challenges:
- Tool-Based Constraints: Dependence on Informatica and SAS limited flexibility and led to vendor lock-in
- Distributed Processing Limitations: Inadequate support for distributed processing affected scalability and performance
- Upgrade and Feature Limitations: New features required costly upgrades, adding to operational and maintenance burdens
- High Costs: Ongoing costs for license renewals and upgrades outweighed the benefits
- Toolset Rigidity: Difficulty in replacing or updating tools constrained developers
- Expensive and Feature-Limited SAS:SAS was costly and lacked modern capabilities compared to contemporary cloud frameworks
- Outdated Hive Version: Older Hive versions did not support essential operations like updates and deletes
- Performance Bottlenecks: Query and batch job performance suffered due to large data volumes (~120 TB)
- Hardware and Server Onboarding Delays: Estimating hardware needs and onboarding new servers was time-consuming and complex
- Technical Debt: The accumulated technical debt hindered our ability to keep up with market advancements
Design Criteria for Cloud Architecture
To address these challenges, we set clear design criteria for our cloud architecture, categorized into minimum expectations and nice-to-have features.
Minimum Expectations:
1. Establish Connectivity to Cloud: Secure and seamless connectivity between on- premises and cloud systems
2. Migrate Data Efficiently: Smooth transition of data from on-premises to cloud
3. Achieve ACID in Data Lake: Implement atomicity, consistency, isolation and durability (ACID) properties to enable updates, deletes and merges
4. Integrate with Power BI: Facilitate seamless integration with Power BI for analytics
5. Enhanced Performance: Improve query and batch job performance over the on- premises setup
6. Tool Continuity: Use existing or suitable alternative tools in the cloud environment
Nice to Have Features:
- Decoupling Storage and Server: Separate data and metadata storage from server resources
- Open Source Data Engineering G Science: Replace proprietary tools with open- source alternatives
- Avoid Tool Lock-In: Minimize dependency on specific vendors to avoid feature limitations and reduce costs
- Flexible Infrastructure: Design infrastructure to scale dynamically based on demand
- Automated Infrastructure Allocation: Automate resource allocation for individual jobs to optimize compute power
- Infrastructure as Code: Use Terraform to automate infrastructure creation and minimize manual errors
- Managed Big Data Software: Leverage managed services for the latest software updates and reduced maintenance
- Modern Data Storage and Format: Adopt modern storage formats (e.g., ORC, Parquet) for wide community support
- Low-Cost Storage and Query Tools: Opt for cost-effective storage solutions and modern querying tools
- Automated Code Deployment: Implement CI/CD to automate and streamline code deployment
- Cloud-Compatible Job Scheduling: Use open-source job scheduling compatible with cloud environments
AWS Cloud Architecture
Our finalized AWS cloud architecture was meticulously designed to meet the above criteria, ensuring a smooth and efficient transition from our on-premises setup.
AWS Cloud Architecture:
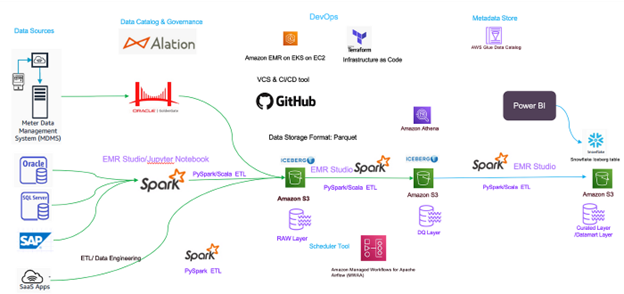
“AWS Cloud Architecture: Modern data infrastructure leveraging AWS services for scalable and flexible data management.”
Key Components
Compute and Container Orchestration:
- EMR on EKS: Utilizes Apache Spark for scalable data processing
- EKS: Manages container orchestration for diverse workloads
Data Lake House:
- Apache Iceberg: Provides a modern table format for the Data Lake, enabling ACID transactions
Data Storage:
- S3: Serves as the primary data storage, offering durability and scalability
Data Engineering and Data Science:
- PySpark: Powers data engineering and data science pipelines
- EMR Studio: Provides a Jupyter notebook environment for interactive data science
Job Scheduling and CI/CD:
- Airflow: Schedules and manages batch jobs
- GitHub: Facilitates version control
- GitHub Actions: Enables continuous integration and deployment (CI/CD)
Data Governance:
- Alation: Manages data governance, ensuring compliance and data quality
Infrastructure Automation:
The cloud infrastructure dynamically scales resources based on demand, eliminating the need for complex hardware estimations
Terraform: Automates infrastructure provisioning and management
Results and Benefits
Migrating to this AWS cloud architecture resulted in significant improvements, such as:
Scalability and Flexibility:
- The cloud infrastructure dynamically scales resources based on demand, eliminating the need for complex hardware estimations
Cost Efficiency:
- We achieved substantial cost savings by transitioning to a pay-as-you-go model and reducing reliance on expensive proprietary tools
Enhanced Performance:
- Query and batch job performance improved dramatically, facilitating faster data processing and analysis
Access to Advanced Features:
- Leveraging AWS services provided access to cutting-edge features and continuous software updates
Simplified Maintenance:
- Managed services reduced the burden of system maintenance, allowing the team to focus on strategic tasks
Improved Data Management:
- The implementation of ACID properties and modern storage formats enhanced data reliability and management
Conclusion
Migrating from an on-premises setup to the cloud was a transformative journey that addressed our challenges and set the stage for future growth. The strategic use of AWS services and a well-planned cloud architecture allowed us to achieve our goals, enhancing performance, scalability and cost efficiency.
For organizations considering cloud migration, our experience underscores the importance of thorough planning, clear design criteria and leveraging modern cloud technologies to build a robust and future-proof data infrastructure.