
With AI shifting from experimental projects to mission-critical production systems, organizations face many challenges in operationalizing ML at scale. Model training and experimentation have converged — the stages with the most obstacles and pain have been removed, thanks to accessible frameworks and cloud-based infrastructure. However, there’s still enormous complexity in achieving scalable, auditable, and cheap production deployment. However, this transition needs more than just functional models; it also requires an AI workloads ecosystem that is reliable, secure and always observable. Enter MLOps, which can seamlessly integrate with DevOps best practices and robust workflows to perform ML models’ continuous integration, delivery and monitoring. In today’s fast-paced AI environment, MLOps requires more than just automation; it must rise to the level of a first-class citizen of cloud-native architecture, i.e., containerization, orchestration and infrastructure as code. As AI initiatives scale within organizations, they hit critical bottlenecks and risks. A primary challenge is the drift between training and production environments. Over time, data distributions evolve — and unless drift is continually monitored and mitigated — the model degrades. Similarly, securing models and data pipelines, particularly in multitenant systems, increases risks regarding data privacy, unauthorized access and adversarial attacks.
Furthermore, GPU utilization costs, data egress and persistent inference workloads constantly increase production use. Without embedded cost monitoring and resource optimization strategies, ML projects tend to become unaffordable. However, it is equally important to meet governance and compliance requirements. Organizations in regulated industries such as finance, healthcare and insurance must have explainability and access control and track the lineage of every model in production. Additionally, regulatory bodies increasingly demand evidence of how models were built, the data they were trained on and how predictions are generated, necessitating detailed audit trails and robust model documentation. It is important to note that scaling AI to production is not just a technical exercise but a strategic imperative requiring a holistic, secure and compliant approach. The foundation is MLOps, but it needs to evolve by being based on architectural principles that enable scalability, observability, economies of scale and governance, by design.
The Reference Architecture: A Scalable MLOps Stack
A scalable MLOps pipeline in an enterprise should contain the following components, a summary of which is presented in Table 1:
1. Feature-Engineering Layer
The foundation of any scalable MLOps pipeline must be robust and responsive data ingestion. In an enterprise environment, incoming data is generated in large volumes and velocity, requiring an event-driven architecture that reliably supports real-time streaming. We often use tools such as Apache Kafka, AWS Kinesis or Azure Event Hubs to capture and route data streams into processing layers. These technologies decouple data producers and consumers, enabling ML systems to consume high-frequency updates from sensors, transactions, logs or user interactions. Event-driven solutions offer scalability and responsiveness for time-sensitive data — an essential feature across fraud detection, recommendation engines and similar areas with real-time processing requirements.
Equally important is the layer that transforms raw data into valuable inputs for ML models. Feature stores such as Feast and Tecton are key (see Figure 1). This centralized feature definition offers version control, consistency and low-latency access to any feature across training and inference contexts. Feature stores decouple the model pipeline from feature logic. Reproducibility is ensured, and ironically, the common problem of ‘training-serving skew’ is avoided. In turn, metadata management systems track dataset versions, transformations and schema changes over time, establishing transparency, traceability and auditability. Real-time ingestion, feature management and data metadata provide the building blocks for reliable, production-ready AI systems that are both solid and scale well.
Figure 1: Tecton’s Feature Store Model
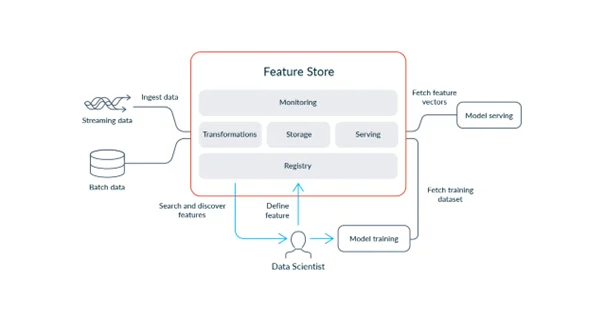
This image shows how a feature store fits into the ML life cycle. It centralizes feature engineering, taking in streaming and batch data, applying transformations and then persisting the result. With the registry, data scientists can search for, define and reuse features to construct training datasets and feed them to models. When inference time comes, we ensure that the same features are served for accuracy purposes and prevent training-serving skews. The feature store is supported for data quality and performance monitoring. It matches nicely with model-training and model-serving pipelines and works to standardize, reuse and govern MLOps workflows.
2. Model-Training Layer
The MLOps pipeline’s computational core — and the most ‘applied’ — is a model-training layer that takes engineered features and outputs deployable ML models. In scalable environments, training workflows are orchestrated using tools such as Kubeflow Pipelines and MLFlow, which provide native integration with Kubernetes to make training reproducible, automated and modular. These pipelines allow teams to run the prescribed directed acyclic graphs (DAGs) of training steps encompassing data preprocessing and model evaluation wrapped in containerized dependencies and environments. Kubernetes provides flexible infrastructure abstraction, high availability and fault tolerance during the training run. Additionally, conducting experiments at scale is needed to systematically test hyperparameters, model architecture and data version selection.
Horizontal pod autoscaling and GPU scheduling via Kubernetes device plugins allow distributed training to handle high-throughput workloads as shown in Figure 2. This setup allows us to parallelize a deep learning job across multiple nodes, which speeds up training and utilizes GPUs more efficiently. This enables governance with the help of MLFlow or Weights & Biases on top of integrated experiment-tracking platforms by version-controlling models, metrics and configurations between different training runs. In addition, these platforms support metadata logging so that downstream auditability and traceability can be achieved — a requirement in regulated industries. The training layer is made both performant and held accountable through these practices. It turns model development from an ad hoc script-based model to a model production pipeline task better built for software engineering best practices and permits continuous experimentation at scale.
Figure 2: Horizontal Pod Autoscaling
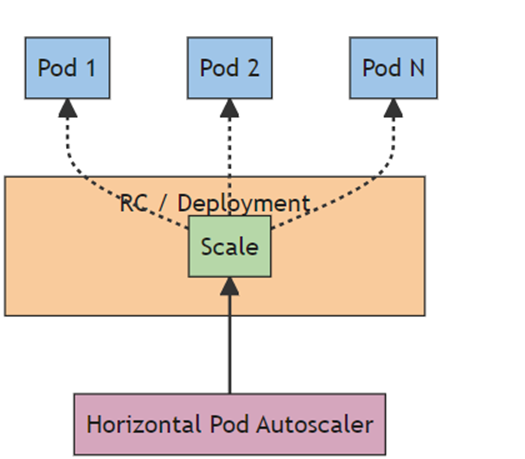
The figure above represents horizontal pod autoscaling in a Kubernetes-based model-training layer. A horizontal pod autoscaler (HPA) looks at resource metrics (e.g., CPU/GPU) to drive the scaling of training pods, aligning with increases in training workloads. The deployment or replication controller (RC) receives the scale signals from the HPA and creates or deletes pods (e.g., Pod 1 to Pod N) accordingly, based on demand. This setup allows the resources to be used efficiently and scaled as needed when conducting model-training tasks. Autoscaling enables roles such as high availability, quick training jobs and parallel processing across multiple pods in distributed ML workflows.
3. Model Registry and CI/CD Layer
The model registry is the single source of truth for managing ML artifacts in a production environment. It also stores the trained models with metadata such as version, training-data lineage, evaluation metrics and life cycle status (staging, production, deprecated, etc.). Tools such as MLFlow Model Registry and SageMaker Model Registry and open-source alternatives are incorporated to enforce consistency and traceability. It allows organizations to better control which model versions are under testing, being validated or being deployed, by tagging models based on readiness or environment. Model proliferation needs to be governed in multi-team or multitenant environments so that we don’t incur technical debt and compliance risks because of this ungoverned proliferation. For centralized control, this is highly vital here.
Complementing the registry, a rich CI/CD pipeline promotes models from development to production. End-to-end workflow solutions such as ArgoCD, JenkinsX or GitHub Actions orchestrate testing, validation and deployment. By adding automated validation gates such as performance benchmarks, bias detection and schema checks, these pipelines will only deploy models that are high-quality and fair enough for production. By embedding these steps into our CI/CD workflows, we remain consistent with repeatability and governance, reduce dependence on humans and avoid manual intervention. In addition, pipelines enable continuous retraining and redeploying based on data drift and new business requirements. This allows MLOps to become an evolving, automated ecosystem of models, which continues to grow at scale and can be safely deployed without compromising compliance, transparency or efficiency.
Figure 3: Model Registry
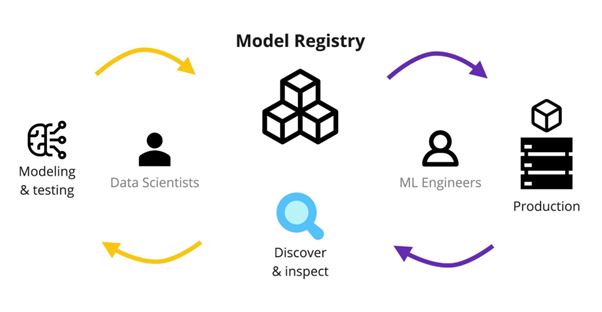
In MLOps, a model registry is a centralized repository that manages the ML model life cycle. It is a model version control system that systematically tracks and manages models from development, through testing, to operational use. The model registry aims to be a secure and well-defined place to store and track ML models. It enables data scientists, engineers and other stakeholders to streamline accessing and deploying their models, promoting consistency and reliability throughout an organization.
4. Model-Serving and Inference Layer
The model-serving layer bridges the training results and practical application. It allows for models to be deployed and consumed in a production environment, most likely in a containerized or serverless runtime. Support for scalable and modular serving infrastructure designed for ML workloads comes from frameworks such as TensorFlow, KFServing, Seldon Core and Vertex AI. These run on REST or gRPC endpoints and support batch or real-time inference with native model versioning. They also help with canary deployments, A/B testing and shadow testing to ensure minimum risk during the rollout of new models. CPU/GPU-based autoscalers based on queue length, request volume or latency metrics optimize resource allocation, enabling elastic performance with a cost-effective ratio under varying workloads.
Inference systems in production-grade environments must always provide security and implement access control. Authentication and authorization protocols such as OAuth2, mutual TLS (mTLS) and IAM-based role enforcement are part of enterprise-grade MLOps architectures protecting model endpoints. They prevent data breaches, misuse and any unauthorized requests for inferences. Secrets management tools like HashiCorp Vault (as presented in Figure 4) are integrated to store and fetch sensitive credentials and tokens securely.
Figure 4: HashiCorp Vault
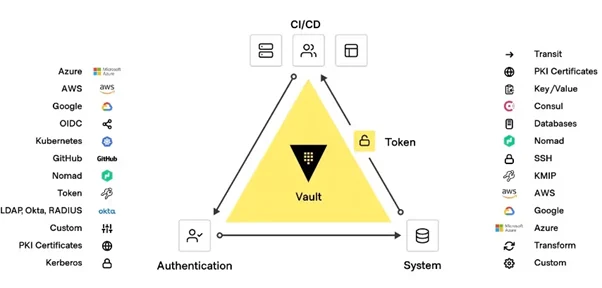
HashiCorp Vault gives you the ability to centrally manage secrets for a much more secure CI/CD workflow. JWT/OIDC, LDAP, TLS certificates, tokens, usernames and passwords are all identities and authentication that Vault can manage. An organization can also use Vault for authenticating its CI/CD workloads for major cloud providers such as AWS, Azure and GCP. With this range of support, organizations can construct flexible workflows and fully decide how their CI/CD pipelines get their data.
Table 1: Core Layers of a Scalable MLOps Stack and Their Key Responsibilities
| Layer | Purpose | Key Tools/Tech | Scalability Feature | Observability and Compliance |
| Data Ingestion | Collect data from batch and streaming sources | Kafka, Spark, Flink | Handles high-throughput, real-time loads | Monitors pipeline delays and data drift |
| Feature Store | Manage and serve ML features | Feast, Tecton | Centralized, reusable features | Logs access, tracks transformations |
| Model Training | Train models using reproducible workflows | Kubeflow, MLFlow, Airflow | Distributed training, HPA for scaling | Logs metrics, version control |
| Model Serving | Deploy and serve models in production | KFServing, Seldon, BentoML | Autoscaling, traffic splitting | Audits, explains predictions |
| Monitoring Layer | Track performance, drift and system health | Prometheus, Grafana, OpenTelemetry | Autoscaling, traffic splitting | Alerts on drift, compliance triggers |
5. Monitoring and Observability Layer
Monitoring and observability are essential for ensuring the health and performance of AI systems in production. The layer has metrics that span both model-specific telemetry and infrastructure-level metrics. Prometheus and Grafana are tools that provide real-time system-level dashboards for metrics such as resource utilization, latency and failure rate. These ensure that the layers on which ML workloads run (compute and networking) function without bogging down. On the model side, observability is the ability to track control (i.e., inputs), responses (i.e., outputs) and performance over time to find degradation. WhyLogs are libraries that enable drift detection, data-skew monitoring and accuracy tracking, which are particularly important for knowing when models suddenly deviate from what they are expected to do. There may be deviations due to changes in user behavior, data quality or even adversarial inputs.
Observability continues in more advanced setups via telemetry and tracing. For instance, with OpenTelemetry, Jaeger, etc., organizations can directly inject trace information into a model-inference pipeline to track a single prediction request across the whole pipeline, from the API gateway, to retrieve features, to the model decision, to the response. With this granular visibility, teams can debug complex failure scenarios and traceability is supported for regulated industries. It logs each prediction with its associated model version, feature set and latency, giving an organization the building blocks of an audit instance.
Figure 5: OpenTelemetry Framework
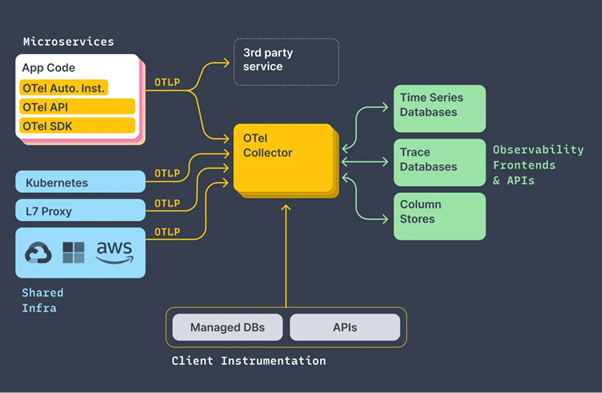
OpenTelemetry is an open-source framework enabling comprehensive observability by collecting, processing and exporting telemetry. Code instrumentation language-specific APIs and SDKs that collect and transmit data are part of it. OpenTelemetry Collector is the core component, which has three parts: For this reason, it is classified into three major sub-components — the receiver (which gathers the data), the processor (which organizes and enriches data) and the exporter (which sends the data to backends like Prometheus or Jaeger). It is modular and only adopts components that a user requires. OpenTelemetry is perfect for monitoring distributed systems and examining an application’s performance without significantly disrupting the code.
6. Governance and Compliance Layer
In the case of any enterprise-grade MLOps architecture challenged with requirements such as governance and compliance, especially for regulated verticals for healthcare, finance and defense, the above practice will be indispensable. This layer makes the AI systems transparent, accountable and auditable throughout the system’s life cycle. Access to sensitive data, model artifacts and production environments is, to an extent, enabled by role-based access control (RBAC) and the telltale sign can be used in IAM and Vault. These controls prevent unauthorized modifications and ensure full traceability and accountability.
Modern governance includes access control and lineage, explainability and fairness assurance. In domains where decisions made by black boxes can change lives or finances or both, explainability artifacts for each prediction are required to be generated and can be embedded within the inference steps of inference pipelines using tools such as SHAP and LIME. These explanations must be human-interpretable and equally technically rigorous to satisfy regulatory standards. Other organizations bypass validation gates by embedding these guardrails within CI/CD pipelines, enforcing those that automatically prevent the deployment of unapproved, biased or outdated models. In addition, every production deployment must be accompanied by the model’s purpose, training data origin and performance metrics. These are increasingly built into the governance features of tools such as Azure Purview, SageMaker Clarify and Google Model Monitoring, ensuring that they follow global standards like GDPR, HIPAA and ISO/IEC 27001.
Cost Optimization in AI Pipelines
AI projects require cost optimization as a fundamental success factor for scalability because they need compute-intensive training functions and GPU-accelerated inference features alongside extensive data pipelines. When MLOps systems lack disciplined cost governance, they often result in uncontrolled expenses, which become especially problematic in cloud-native environments with elastic resources. Organizations now integrate FinOps principles into their MLOps pipelines to achieve financial accountability while improving visibility and team collaboration between engineering personnel and finance departments. Life cycle policies applied to artifacts and datasets in research projects automatically delete or archive outdated experiment results, leading to a substantial reduction in storage costs. The system maintains valuable artifacts for retraining and audit purposes but prevents unneeded data hoarding.
Companies can save on costs by applying custom tags and labels at the job or user level to attribute GPU expenses. Detailed resource monitoring is made possible through this approach, which enables precision tracking of consumption data for internal budget distribution methods. Off-peak scheduling of batch jobs enables organizations to use lower-demand pricing models while avoiding conflicts with latency-sensitive services. Real-time endpoint monitoring allows organizations to automatically identify idle model servers for scaling down, thus reducing the number of active containers or pods that waste expensive GPU computing power. Organizations must connect cloud-native cost monitoring tools such as AWS Cost Explorer, Azure Cost Management and GCP Billing Reports to telemetry platforms, including Prometheus, for operational deployment of these strategies. Financial discipline develops through dashboards that display cost data at various organizational levels, including models, predictions and teams. The token-level pricing system of GenAI and LLMs needs institutionalized FinOps implementation within MLOps architecture as an essential requirement for sustainable innovation at scale. Sustainable innovation needs a framework such as this one, at scale.
Ensuring Observability Across the ML Life Cycle
MLOps observability goes beyond traditional infrastructure monitoring and is a multi-dimensional compendium. System uptime and resource utilization are still critical, but for ML systems, bringing insights into how model-specific signals affect network and business performance becomes essential and key. In order to sustain trust and performance over time, observability must have capabilities like data-drift detection, model-decay monitoring and traceability from the end-to-end pipeline. These facets allow engineering and data science teams to catch subtle failures early, triage incidents quickly and have end-to-end accountability in the ML life cycle.
Data-drift detection maintains the relevance of the model. Using this technique, alerts surface when these discrepancies are found by comparing the statistical distribution of live data with training datasets. When high cardinality or time-sensitive features drift in their distributions, the failures become silent, where the predictions are technically operational but functioning in an inaccurate or biased way. This is complemented by model-decay tracking, in which we measure how accuracy, precision and recall change over time. It correlates with upstream data changes, seasonal trends or changes in customer behavior when there are variations in performance. These alerts are generally effective when integrated into dashboards and incident workflows as part of effective observability stacks, triggering model retraining or rollback to prevent an impact on business.
MLOps teams should be able to enable inference logging at the appropriate level to support traceability and tie each prediction to its specific model version, its feature pipeline and the input data that produced it. This is essential for debugging anomalous predictions, auditing decision paths and ensuring regulatory compliance. Tools such as OpenTelemetry and Jaeger facilitate distributed tracing for containerized pipelines, and there are trace injection techniques that let you correlate prediction latency, model provenance and input lineage between different services. If inference APIs can be instrumented to emit trace IDs, engineering teams can stitch back workflows from ingestion to prediction. The resulting end-to-end visibility also enables better root cause analysis while at the same time providing SLAs for model performance and latency.
Building Compliance Into the MLOps Stack
With ML finding wider adoption in regulated industries such as finance, healthcare and defense, compliance must become a first-class requirement rather than an afterthought. Strict data governance mandates and ethical standards rule these sectors and insist on transparency, explainability and auditability in AI-driven decision-making. Hence, they need to be supported natively, not as an add-on. MLOps stacks must evolve by including compliance as a core part of the model development, deployment and monitoring life cycle. In other words, each model deployment, rollback or update must have tamper-proof audit logs to record each model deployment and the associated decisions and changes to facilitate internal and external review.
Documentation is one of the core pillars of AI compliance, and specifically, the purpose of the model, the lineage of the training data, the feature sources and the validation metrics must be documented. If you’re working in a team, you’re also responsible for ensuring that the model’s intent is clearly stated, data origins are verifiable and feature pipelines are versioned. Data cataloging, policy management and bias detection are supported by cloud-native services such as Azure Purview, Google Cloud Model Monitoring and Amazon SageMaker Clarify, which assist organizations in complying with regulations such as GDPR and HIPAA or standards like ISO 27001.
Another cornerstone of responsible AI use is explainability when using complex or black-box models such as deep neural networks or ensemble methods. Regulatory expectations often involve an explanation accompanying a prediction, for example, why a loan was denied or how a patient was triaged. At inference time, tools such as SHAP, LIME and Amazon SageMaker Clarify generate explainability artifacts that can be stored with the predictions for future auditability. These outputs must be available to data scientists, compliance officers, auditors and domain stakeholders. Through the integration of compliance at every step of the MLOps pipeline, from design to deployment, enterprises can preclude legal risk, increase accountability and create trust in AI systems working in delicate spaces.
GenAI Considerations
The adoption of LLMs and GenAI has brought tremendous change in the MLOps ecosystem, with a new operational discipline — LLMOps. In contrast to traditional ML pipelines, GenAI systems have extensive challenges involving token-level billing, uncertainty in latency and the requirement for highly adaptable model behavior. This is an essential financial issue, strictly about managing token-cost tracking.
Prompt caching is another area in GenAI operations that is important and must be optimized. With repeated queries, especially popular prompts or ones with deterministic results, it is possible to intercept the questions and serve them from cache layers to alleviate GPU load and response times. Doing this reduces computing costs and improves system responsiveness at peak times. However, prompt injections are a serious security concern alongside caching. The model may also be susceptible to malicious users who craft prompts to override system-level instructions or extract confidential data.
From the governance perspective, GenAI pipelines represent a novel challenge. Data anonymization is essential, as data are increasingly fine-tuned or retrained on proprietary data for LLMs. The training datasets must be pre-processed through techniques such as masking or removing personal identifiable information (PII) or sensitive data using governance tools. Additionally, GenAI has added observability beyond standard metrics such as latency or throughput. Finally, it must be monitored at the content level, i.e., toxicity, bias, factuality and hallucination rates.
Conclusion
In modern enterprises, scaling MLOps is far beyond just orchestrating tools — it involves taking a strategic architectural approach with principles focused on reproducibility, security, cost efficiency and governance. When AI systems penetrate deeply into business operations, organizations will have to move away from ad hoc experimentation to profound, cloud-native ML platforms. These platforms need to be FinOps-ready for continuous cost visibility and cost optimization, SecOps-ready to secure data and models across the ML life cycle and AIOps-ready to provide intelligent automation, monitoring and issue remediation. Every piece in the stack, from data ingestion to model deployment, must be a first-class citizen in a well-governed, scalable infrastructure that supports a production-grade MLOps stack. Reproducibility means that people can validate and audit outcomes. Observability means problems are picked up and fixed before impacting users. Thus, compliance ensures that models fit ethical, legal and organizational standards. Together, these pillars form a way of ensuring a culture of responsible AI. The future of AI in production lies with enterprises that view their ML pipelines not just as a bunch of technical workflows, but rather as mission-critical systems with metrics important for transparency, efficiency and ultimately, sustained value. Trustworthy, enterprise-grade AI deployment is no longer optional — it’s built upon building pipelines that are performant, traceable, secure and cost-effective, by design.