
Data architecture has changed rapidly and fundamentally in recent decades as the demands of the markets have evolved. These next-gen data architectures are founded on new technologies such as cloud-based solutions, including data lakes, lake warehouses, delta lakes, data fabric, and data mesh, and can handle the growing volume, variety, velocity, veracity, visibility and value of contemporary data. These changes help businesses respond quickly to new opportunities and better inform decision-making.
Types of Data Architectures
Data architecture defines a high-level architectural approach and concept to follow, outlines a set of technologies to use and states the flow of data that will be used to build the data solution to capture big data. No one-size-fits-all architecture exists; hence, it is challenging to select a data architecture. Existing data architecture types can be roughly divided into two categories: (relational databases and warehouses) and modern data architectures (modern data warehouses), which include microservices, cloud-based (data lake and data fabric) and event-driven architectures.
In monolithic architecture, the data from the application is copied directly into a relational database. It is increasingly challenging to process and analyze that data without long delays using relational databases. RDWs also centralize data from multiple applications to improve reporting (Figure 1). There are two data spaces: Online transaction processing databases (OLTP) and online analytical processing (OLAP), which is a data warehouse to answer business analytical questions.

Figure 1: Monolithic architecture
Microservices architecture is an upgrade of service-oriented architecture. Each service functions as an independent deployment unit. These units are distributed, decoupled from each other, and connected through remote communication protocols (Figure 2). The architecture is loosely coupled with moving target NoSQL databases. Because the data is no longer structured and relational, conventional relationships break apart in microservices architecture-based data warehouses. This type of architecture is typically implemented to enable scalability.

Figure 2: Microservices architecture
Cloud architecture is a next-gen architecture that primarily includes processing units that implement business logic and virtual middleware and are responsible for communication, session maintenance, data replication, distributed processing and deployment of processing units. Some models support a pay-as-you-go strategy for computing, storage, and service. One example of cloud architecture (Figure 3) is the data lake, in which structured, semi-structured, and unstructured data from multiple sources are stored in secure, centralized repositories. Despite its many benefits, this architecture comes with the intrinsic risk of data swamp, which results from a poorly managed data lake that lacks appropriate data quality and data governance practices to provide insightful learning, rendering the data useless.
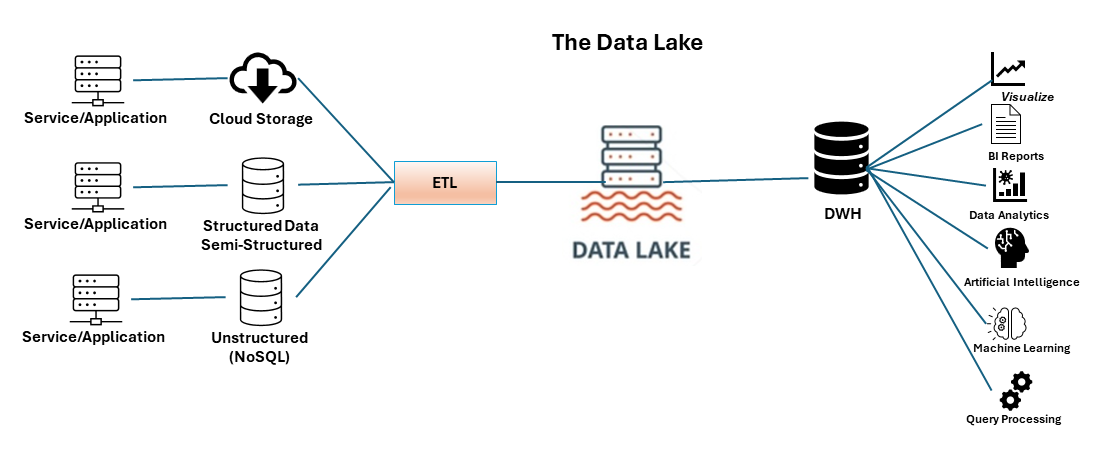
Figure 3: Data lake cloud architecture
Data fabric is an architecture that facilitates end-to-end integration of various data pipelines and cloud environments using intelligent and automated systems. By leveraging data services and APIs, data fabrics pull together data from legacy systems, data lakes, data warehouses, SQL databases and apps, providing a holistic view of business performance. A data fabric abstracts away the technological complexities used in data movement, transformation, and integration, making all data available across the enterprise (Figure 4).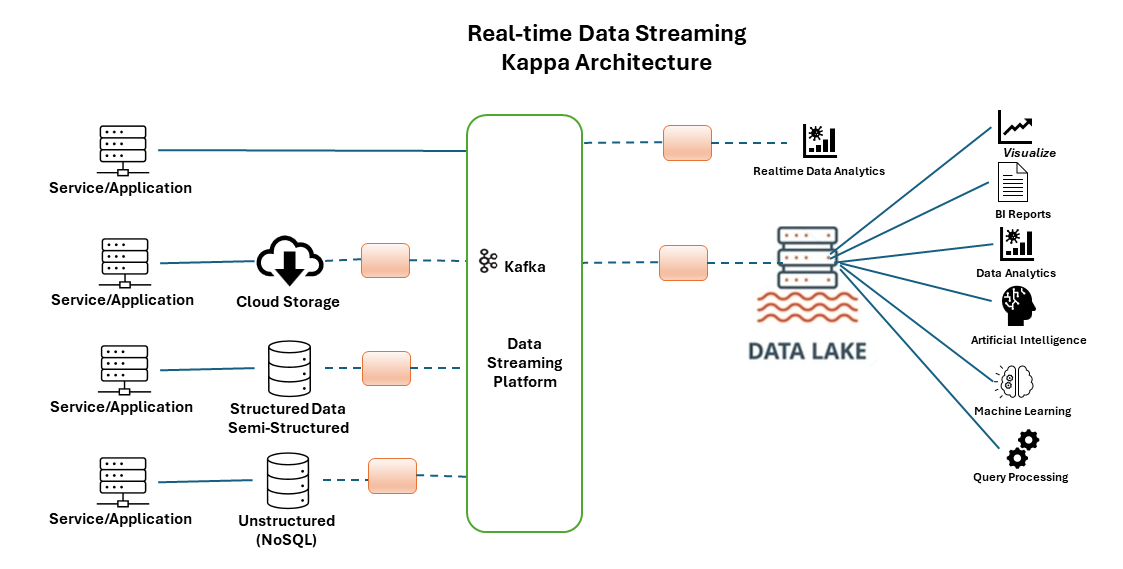
Figure 4: Data fabric cloud architecture
Event-driven architecture communicates data as messages through events. The structure includes an event queue that receives events (e.g., insert, update, delete, or copy), an event mediator that distributes them to different business logic units, an event channel that connects the event mediator and the processor’s contact channel, and an event processor that implements business logic. This enables data streaming for real- or near-real-time data pipelines.
Lambda architecture combines batch and stream processing (Figure 5). Data is processed in a batch layer for comprehensive analysis and a speed layer for real-time processing.

Figure 5: Lambda architecture
Kappa architecture focuses on handling only real-time data processing, removing the batch processing layer (Figure 6). Kappa architecture is also designed to handle high levels of concurrency and high volumes of data. This simplifies the stack but requires strong stream processing capabilities. This architecture is used when simplicity and reduced latency are priorities.
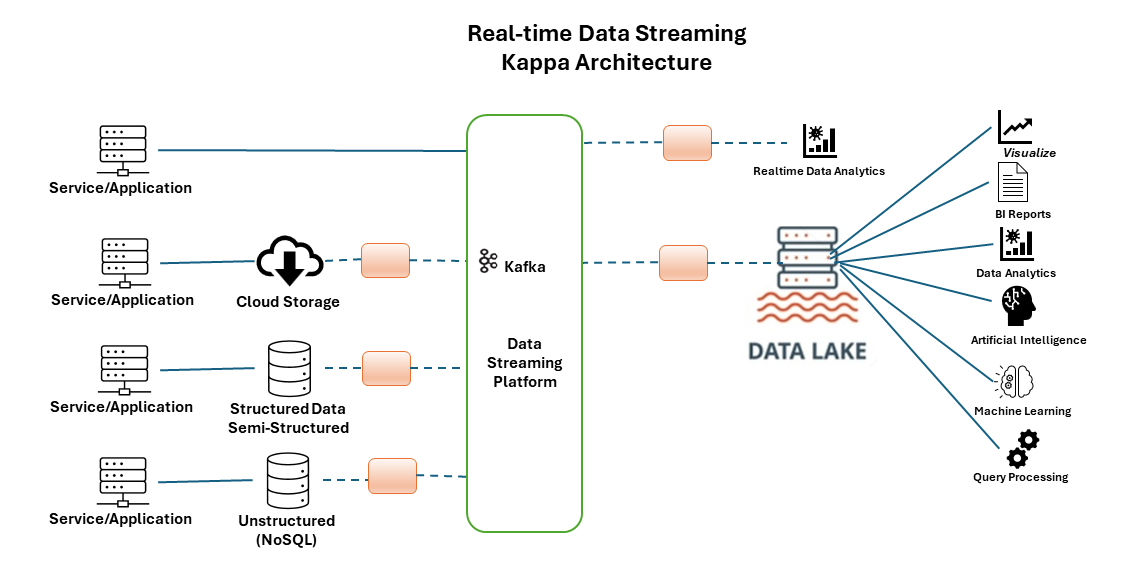
Figure 6: Kappa architecture
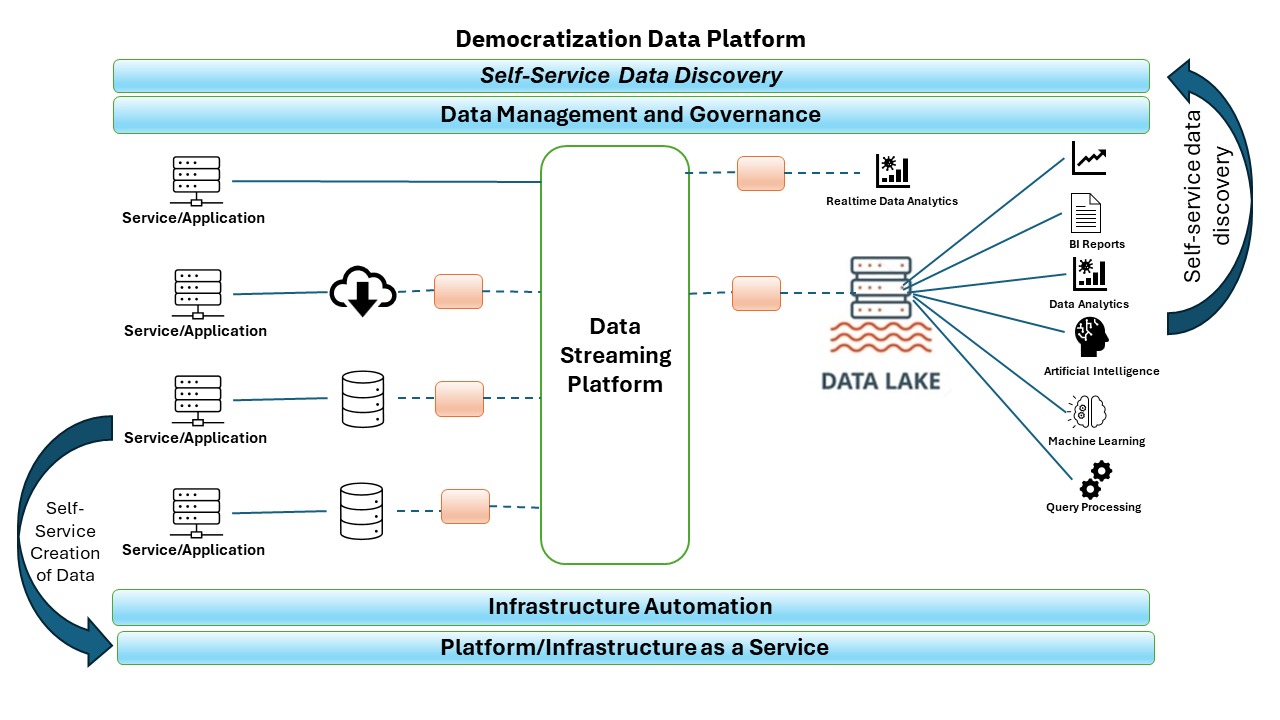
Data warehouse, data lake and data fabric architectures are all centralized architectures where the IT team creates and owns all analytical data. A data mesh (Figure 7) is a decentralized data architecture with four specific characteristics. First, it requires independent teams within designated domains to own their analytical data. Second, data is treated and served as a product to help the data consumer discover, trust and utilize it for whatever purpose they like. Third, it relies on automated infrastructure provisioning. Fourth, it uses governance to ensure that all the independent data products are secure and follow global rules.

Next-Gen Data Architecture Characteristics
As organizations build their roadmap for tomorrow’s applications, including AI, blockchain and Internet of Things (IoT) workloads, a next-gen data architecture will be necessary to support the data requirements. The top eight characteristics of next-gen data architecture are:
- Cloud-native and cloud-enabled, allowing the data architecture to benefit from the cloud’s elastic scaling and high availability.
- Robust, scalable and portable data pipelines that combine intelligent workflows, cognitive analytics, and real-time integration in a single framework.
- Seamless data integration, which uses standard application programming interfaces (APIs) to connect to legacy applications.
- Real-time data enablement, including validation, classification, management and governance.
- Decoupled and extensible, preventing dependencies between services and open standards enabling interoperability.
- Suitable for AI and capable of using machine learning (ML) and AI to adjust, alert and recommend solutions to new conditions. ML and AI can identify data types, fix data quality errors, create structures for incoming data and identify relationships for fresh insights. They can also recommend related data sets and analytics.
Next-Gen Data Architecture Delivers Competitive Advantages
One of the most compelling reasons for smaller enterprises to use next-gen data architectures is their ability to level the playing field. With pay-as-you-go models, smaller firms can leverage powerful technology to manage their data competitively. For example, smaller banks that want to compete with the larger national and global institutions can do so with decentralized data architectures. Another benefit is the capability for real-time marketing, in which search engines leverage next-gen data architectures to market to their users in real time.
The evolution of data architecture has created more opportunities for organizations to manage and leverage data to improve decision-making. Organizations’ ability to adapt to these changes and deploy next-gen data infrastructure will determine future success by innovating effectively. Such an adaptation will ensure organizations can scale their data analytics and have more flexibility and the much-needed real-time capabilities that are critical to staying competitive in today’s data-driven business environment.