
Large Language Models (LLMs) are the backbone of today’s rapidly evolving AI landscape, powering everything from intelligent chat assistants to advanced data analyzers. As these models become increasingly complex and prevalent in the applications we use daily (some estimate there will be around 750 million LLM apps built by 2025), ensuring their reliability and performance becomes more important.
Enter observability tools like OpenTelemetry; enhanced by wrappers around the OpenTelemetry SDK that provide auto-instrumentation for LLMs, like OpenLIT, and visualization platforms like Grafana, these tools make it easier to monitor and analyze LLM applications.
Why Observability Matters for LLM Applications
Application observability isn’t a new concept, but integrating LLMs can complicate things significantly. LLMs, with their intricate workings and massive datasets, are complex beasts. As we’re still in the early stages of integrating LLMs into various technologies and tools, setting up robust observability should be one of the first steps.
The ability to observe what’s happening inside these applications in real time through logs, metrics and traces can mean the difference between smooth operations and frustrating outages. Beyond the end-user impact, observability can also help keep tabs on costs (according to TensorOps, the cost of incorporating LLMs into your application can vary from a few cents for on-demand use cases and increase to $20,000 for hosting a single instance), ensure latency isn’t lagging and avoid hitting rate limit requests.
Why OpenTelemetry is the Right Choice
OpenTelemetry is an open-source observability framework that collects and exports monitoring data in a way that isn’t tied to any particular vendor. It sets the standards for how data should be collected and processed. It’s great for LLM applications because it works with many different monitoring tools like Grafana.
It’s perfect for LLM applications because tracing, a core signal in OpenTelemetry, helps in understanding the sequence of events. This is especially important when using orchestration frameworks like LangChain or LlamaIndex. Tracking the sequence of operations helps you to understand the workflow, making debugging and root cause analysis simpler and more effective.
What to Track: Key Signals to Monitor
Using LLMs in applications is different from traditional machine learning models. LLMs are often accessed through external API calls, so it’s important to capture the sequence of events (traces) and analyze aggregated data (metrics).
Collecting this information is not just general API monitoring; the data gathered, especially prompts and responses combined with cost and tokens, provides a complete picture of the application’s performance. The collected data can then help you score the application on evaluation tests like Prompt Evaluation, Model Performance Evaluation, PII Detection and more.
Here are the key signals to monitor:
Traces
- Request Metadata:
- Temperature: Measures how creative or random the output should be.
- top_p: Controls how selective the model is with its output text choices.
- Model Name or Version: Helps track performance changes with updates.
- Prompt Details: The inputs sent to the LLM, which can vary greatly.
- Response Metadata:
- Tokens: Directly impacts cost and measures response length.
- Cost: Important for budgeting and managing expenses.
- Response Details: Characteristics of model outputs and potential inefficiencies.
Metrics
- Request Volume: Total number of requests made to the LLM service to understand usage patterns.
- Request Duration: Time taken to process each request, including network latency and response generation time, to understand service performance.
- Costs and Tokens Counters: Tracking total costs and tokens over time for budgeting and cost optimization.
Prerequisites
Before jumping into how to instrument LLM applications with OpenTelemetry, you should have a basic understanding of LLM technologies and be familiar with the programming language of your choice.
Instrumenting an LLM Application: Manual vs. Automated Approaches
There are two main ways to use OpenTelemetry in LLM apps:
- Manual Instrumentation with OpenTelemetry SDK: This is where you decide exactly what to monitor and gather data on. It offers precise control but takes a lot more time to set up.
- Automated Instrumentation with OpenLIT: This easier method automatically keeps track of all of the LLM Inputs and Outputs and assigns associated costs to each request. It’s a faster way to get observability.
Manual Instrumentation with OpenTelemetry SDK: A Guideline
To manually instrument your LLM application, follow these steps:
- Install the OpenTelemetry SDK: Install the SDK tailored for the language of your application.
- Integrate Trace Collection: Add code to collect trace data within your application.
For example, wrapping API calls to OpenAI Chat Completions in spans can capture valuable performance metrics and pinpoint issues down to specific operations:
“`python
from opentelemetry import trace
from opentelemetry.trace import SpanKind
tracer = trace.get_tracer(__name__)
with tracer.start_span(“openai.chat.completions”, kind=SpanKind.CLIENT) as span:
response = client.chat.completions.create(
model=”gpt-4″,
messages=[
{“role”: “system”, “content”: “You are a helpful assistant.”},
{“role”: “user”, “content”: “Hello!”}
]
)
span.set_attribute(“gen_ai.response”, response.completion.choices[0].message)
“`
However, as you can see, this type of instrumentation can become complex and cumbersome to implement for each LLM request, significantly increasing the complexity of your application.
Automated Instrumentation: Quick Solution with OpenLIT
OpenLIT offers a straightforward path to automated instrumentation. By using the OpenLIT SDK, developers can automatically capture essential telemetry data with just one line of code addition. This SDK smartly identifies common LLM operations and ensures they’re observed without heavy lifting from developers.
“`shell
pip install openlit
“`
Setup: Set the following environment variables
“`shell
export OTEL_EXPORTER_OTLP_ENDPOINT=”YOUR_OTEL_ENDPOINT”
export OTEL_EXPORTER_OTLP_HEADERS=”YOUR_OTEL_HEADERS”
“`
Initialize the SDK at the start of your application entry point.
“`
Import openlit
openlit.init()
“`
You can also choose to set a custom application name and environment by setting the `application_name` and `environment` variables in the openlit.init() function arguments
Visualizing in a Grafana Dashboard
Once your LLM application is instrumented with OpenTelemetry, it’s time to visualize and analyze this data. There are a few options offering customizable dashboards that bring your telemetry data to life, but the screenshot below shows Grafana. Whether you’re tracking API latencies or understanding query efficiencies, Grafana’s versatile platform supports dynamic, insightful visualizations.
Here is a sample dashboard that you can import (Thanks to the OpenLIT Team for building this!)
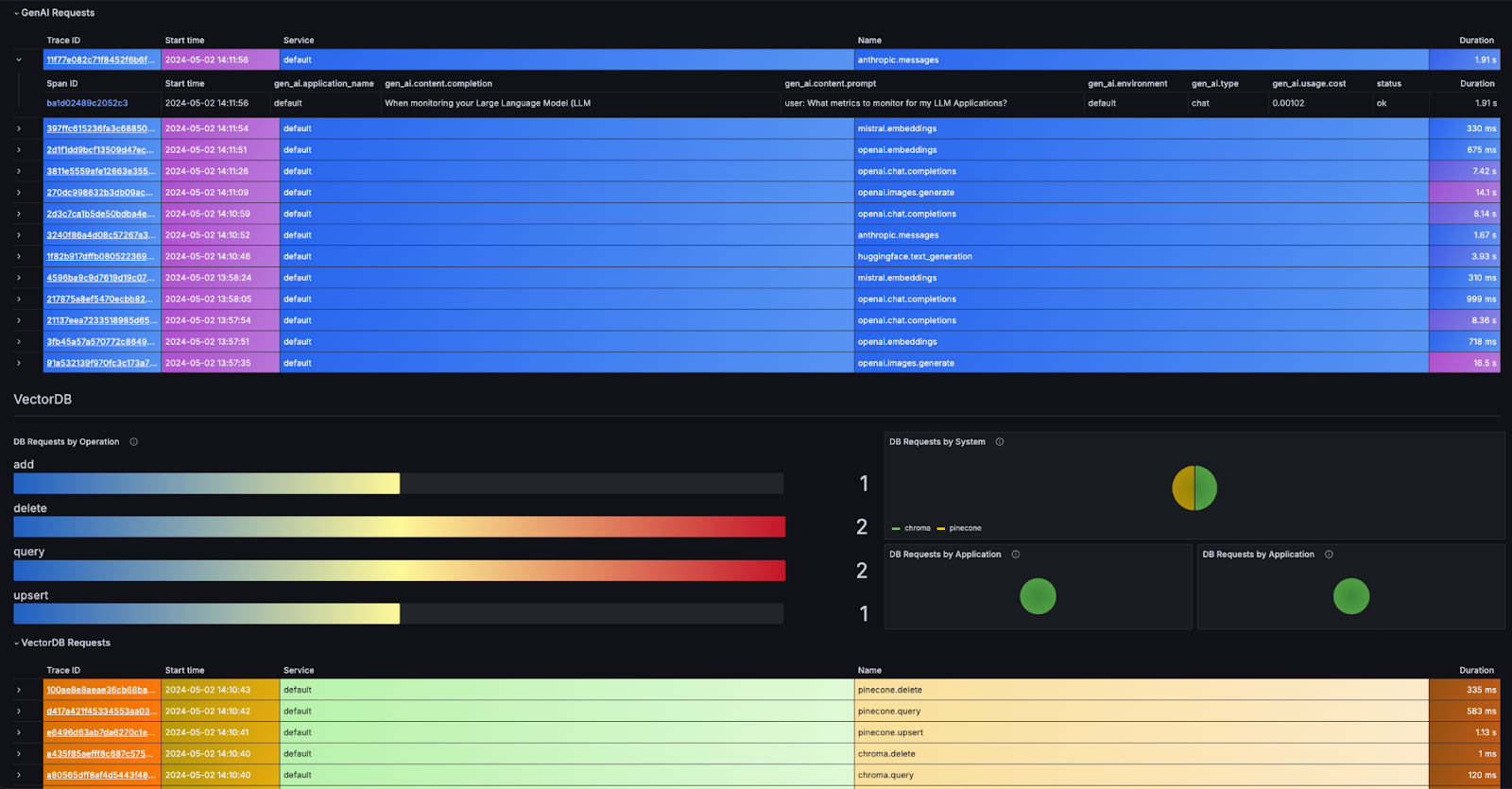
The Grafana dashboards provide a comprehensive overview of your LLM application’s performance and usage. Users can monitor metrics like total successful requests, request rates, usage costs, and token consumption. Additionally, request duration distributions and top-used models are displayed. Detailed trace information and database operations are also visualized, offering insights into the sequence of events and database interactions.
This aggregated data helps users understand the app’s performance, manage costs and identify bottlenecks. The insights gained from these dashboards facilitate further evaluation tests like Prompt Evaluation and Model Performance Evaluation, enabling optimizations for better reliability and efficiency.
Conclusion
When it comes to LLM applications, observability is not just a nice to have; it’s a critical component of operational success. OpenTelemetry, with its open standards and wide industry support, provides a solid foundation for building observability into these complex systems.
By combining manual and automated instrumentation strategies with the analytical prowess of a tool like Grafana, developers can achieve a deep understanding of their LLM applications, leading to improved performance, reliability and user satisfaction.