
Large language models (LLMs) are proliferating and have the potential to change the world. The technology is being applied in many areas of our lives, from health care to customer service.
LLMs are an exciting new frontier for delivering services, but also require a new kind of tech stack that supports app development, deployment and maintenance with a focus on quality and accuracy.
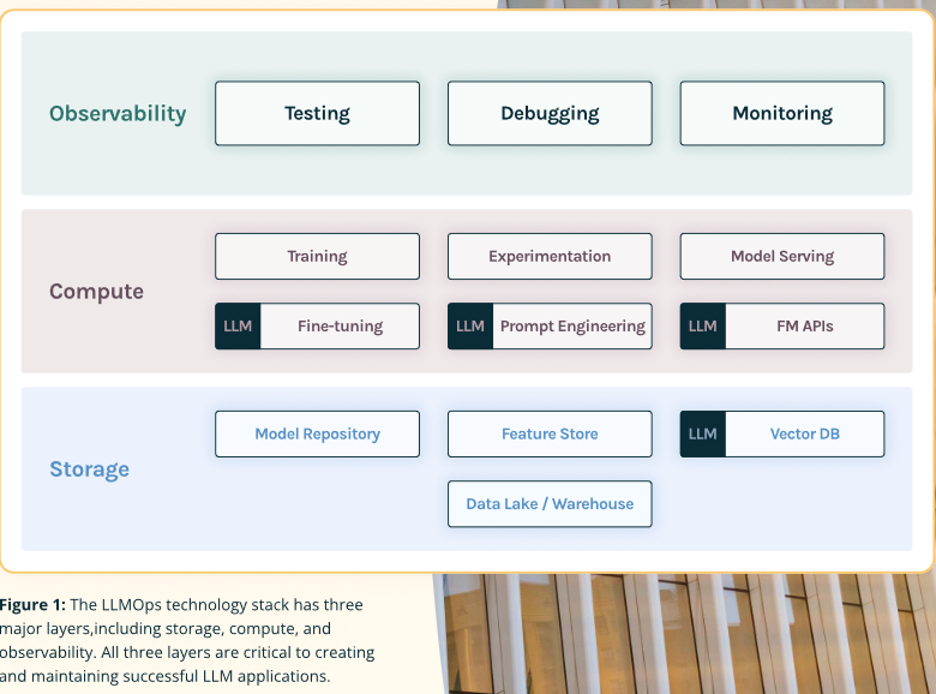
For the past year, I’ve been working directly with developers helping them to build out their infrastructure for LLMs. We’ve learned that the three essential elements of the LLMOps tech stack are: Observability, Compute and Storage. All are required to ensure successful function of LLM apps.
Observability consists of testing, debugging and monitoring. Compute consists of training, experimentation, model serving, fine-tuning, prompt engineering and FM APIs. Finally, storage consists of model repositories, feature stores, vector DBs and data lakes/warehouses.
Spanning these three elements, there are 10 typical workflow steps that need to occur in order. I’ve seen firsthand how these steps combine to ensure LLM app quality in the real world:
1. Foundation model training. This is composed of generative pre-training and supervised learning. During generative pre-training, an LLM is trained on vast amounts of data to predict the next word after a sequence of text. This allows generative language models to be good at producing human-like text. The training process is accelerated using advanced hardware and software stacks that enable massive parallelization from vendors such as Intel and NVIDIA. The next step is supervised learning, in which language models are trained on specific examples of human-provided prompts and responses to guide their behaviors.
2. Data preparation: There are several flavors of data preparation tasks with associated tools. LLM creators like OpenAI, Google, Meta etc. prepare data for generative pre-training – often very large volumes of unlabeled data. Recently, we are also seeing more carefully curated smaller data sets used to train LLMs that are orders of magnitude smaller than state-of-the-art models but competitive in certain tasks. These data sets could, for example, include a set of prompts and responses to fine tune a chatbot to a domain-specific use case, such as for customer service for ecommerce. LLM applications can also leverage Retrieval Augmented Generation (RAG), which involves augmenting LLMs with a knowledge base of documents that serve as a source of truth and can be queried. One example of this paradigm is Morgan Stanley’s use of OpenAI models to create a chatbot for their financial advisers.
3. Vector DB index construction: RAGs, such as the Morgan Stanley wealth management chatbot, require the knowledge base of documents to be split up, converted into embeddings, and stored in a vector database, which is indexed to support querying. Vector databases, such as Pinecone and Weaviate are thus seeing rapid adoption.
4. Model fine-tuning: LLMs need to be fine-tuned, often on private data held by enterprises and small businesses. These data sets could, for example, include a set of prompts and responses to fine tune a chatbot to a domain-specific use case, such as for customer service for ecommerce. LLM providers such as OpenAI and Google are increasingly making fine-tuning APIs available for their models. Fine-tuning APIs is also available for open source LLMs hosted on services, such as AWS Amazon SageMaker JumpStart.
5. App Creation: LLMs are often connected to other tools such as vector databases, search indices or other APIs. RAGs and Agents, mentioned above, are two popular classes of LLM applications. Building by chaining has emerged as a popular paradigm with tools like Haystack, LlamaIndex and LangChain seeing widespread developer adoption.
6. Prompt-engineering, tracking, collaboration: When developers are creating prompts tailored for a specific use case, the process often involves experimentation: The developer creates a prompt, observes the results and then iterates on the prompts to improve the effectiveness of the app. Tools such as TruLens and W&B Prompts help developers with this process by tracking prompts, responses and intermediate results of apps and enabling this information to be shared across developer teams.
7. Evaluation and debugging: Systematic evaluation and debugging of LLMs and LLM apps based on RAGs and Agents are absolutely essential before they are moved into production. A first step in this direction is often to use human evaluations and benchmark datasets to evaluate LLMs. While useful, these methods do not scale. Recent work has shown the power of programmatic evaluation methods to evaluate LLMs and LLM apps, including OpenAI Evals and TruLens. Evaluations help ensure that LLM apps are honest, helpful and harmless.
8. Model deployment and inference: LLMs are deployed by and available via APIs by the major cloud providers, including AWS, GCP, Azure as well as hosted by LLM providers, such as OpenAI and Anthropic. Platform companies, such as Databricks, MosaicML and Snowflake also offer model deployment services.
9. App hosting: App hosting services such as Vercel are increasingly being used to deploy LLM apps faster.
10. Monitoring: Deployed LLMs and LLM apps need to be monitored for quality metrics (in line with the evaluation metrics described above) as well as cost, latency and more. Vendors included TruEra and HoneyHive.
The Evolution of LLMs
The LLM space is evolving rapidly, and developers are looking to scale. Establishing a strong tech stack and repeatable workflow provides the structure needed to both accelerate LLM app deployment and ensure quality.