
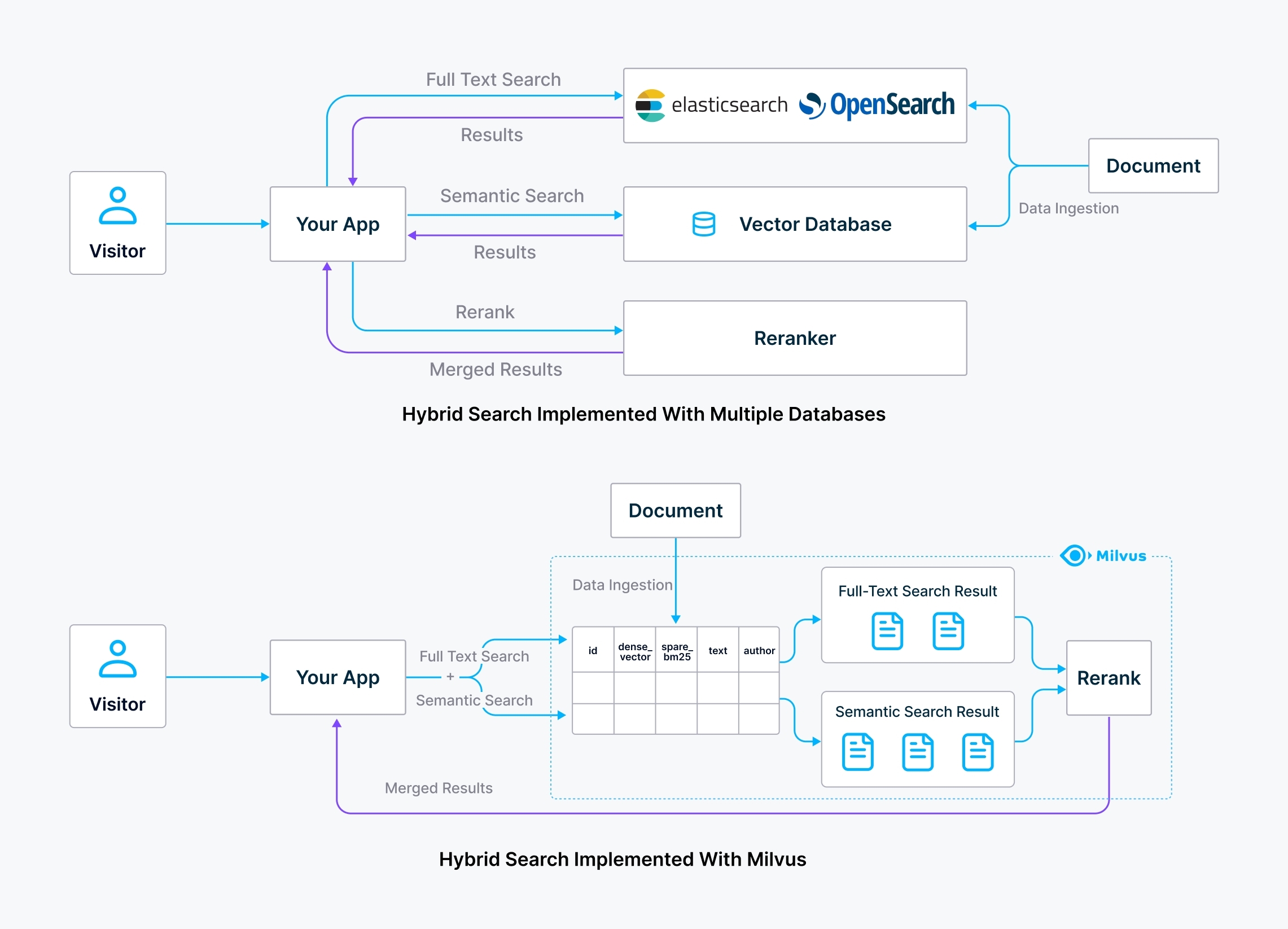
Zilliz this week updated its open source Milvus vector database to provide an offering that is now 30 times faster and less expensive than alternative approaches that require data science teams to rely on separate vector databases and keyword search platforms.
Based on Sparse-BM25 algorithms for converting text into embeddings that can be consumed by artificial intelligence (AI) models, Zilliz claims version 2.5 of the Milvus platform can process one million vectors in six milliseconds.
That capability makes it feasible to use Milvus in a wider range of real-time AI applications running on a range of embedded systems, including mobile phones and autonomous vehicles, says Zilliz CEO Charles Xie.
At the same time, overall costs are lower because there is no need to acquire and manage separate platforms. “We consolidate data management,” says Xie.
That approach also streamlines the number of calls to application programming interfaces (APIs) that otherwise would need to be made, he adds.
Finally, it’s simpler to centrally secure one rather than two data infrastructure platforms, notes Xie.
The performance levels required by data science teams will naturally vary by use case. In some instances, using a legacy database that has been extended to include support for vectors might be sufficient for retrieval-augmented generation (RAG) techniques that extend the capabilities of a large language model (LLM) beyond the initial data set it was trained on. However, in production environments that require data to be processed in near real time, most organizations are going to opt for a platform designed from the ground up for that specific type of use case, says Xie.
Competition among providers of data management platforms in the age of AI is naturally fierce. Many organizations might wind up using multiple platforms as various data science teams pursue different use cases. However, when it comes to deploying AI models in production environments, tolerance for any kind of significant amount of overall application latency is not going to be very high.
In fact, many of the data management platforms that were used to create an AI proof-of-concept might need to be replaced when an application is deployed at scale in a production environment.
In the meantime, there has never been a greater appreciation for the nuances of data management. The rise of AI is driving many organizations to finally revisit the way they manage data. More often than anyone cares to admit, data management practices are either antiquated or simply didn’t exist in any formal way.
Less clear is who within organizations will ultimately assume responsibility for data management in the AI era. There is no doubt that data science teams forced the issue, which resulted in organizations hiring data engineers to support their efforts. The challenge now is finding ways to reduce the total cost of data management by, among other things, reducing the level of expertise that is today required.
In the short term, however, the difference between success and failure when it comes to AI has as much to do with the expertise of data engineers that data scientists rely on to provide them with access to the right data, in the right place, at the right time.