
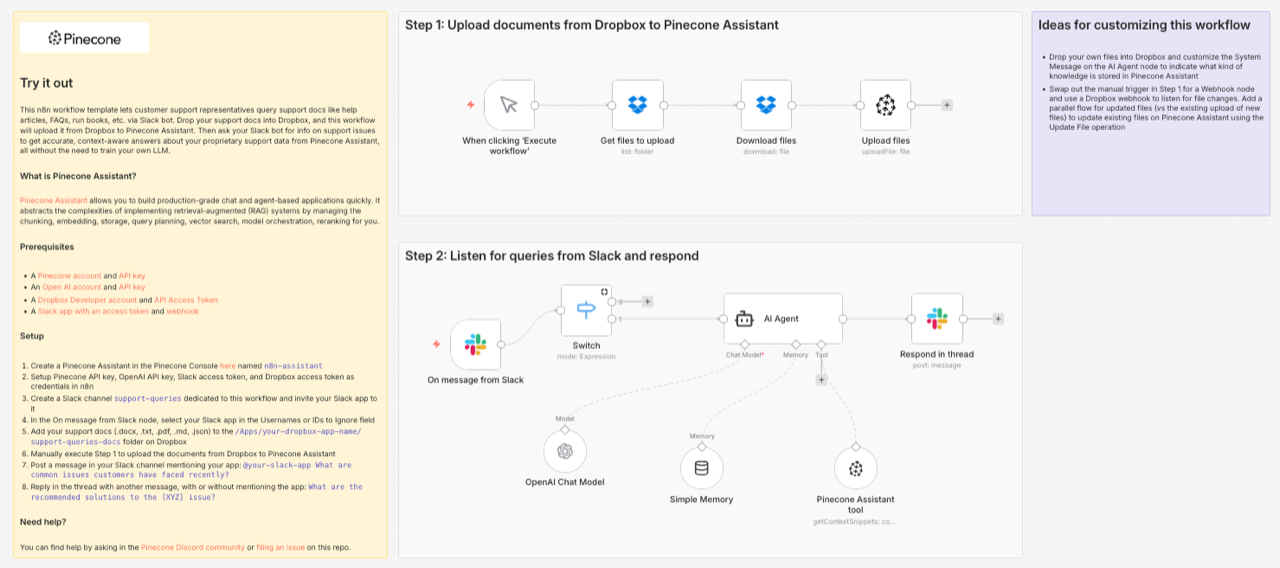
Pinecone has partnered with n8n to create an artificial intelligence (AI) agent that automates retrieval augmented generation (RAG) workflows that are used to expose large language models (LLMs) to more recent and relevant data.
The Pinecone Assistant node for n8n takes advantage of the automation framework developed by n8n to upload files into the vector database provided by Pinecone. Instead of having to create a pipeline to manually upload, for example, PDFs, it’s now possible to automate the entire workflow, including chunking, embedding, vector search, query planning, and reranking.
That capability enables organizations to streamline workflows so they can manage RAG as a service rather than as a batch-oriented process, says Jenna Pederson, staff developer advocate for Pinecone. In effect, any data source that n8n can access can now be queried via a node in the n8n automation framework that runs Pinecone Assistant, she adds.
That’s critical because as organizations start to build and deploy AI agents the workflows they are being added to are becoming more dynamic, notes Pederson. “Workflows are going to become much more asymmetrical,” she says.
It’s not clear to what degree organizations are embedding RAG-based workflows into business processes but there is a clear need to dynamically expose data to large language models (LLMs). A recent Futurum Group survey finds the global data intelligence, analytics, and infrastructure (DIAI) market is projected to grow at a 17% compound annual growth rate through 2028 off a base of $541.1 billion in 2026 to exceed $1.2 trillion by 2031.
Specifically, AI development and operations are forecast to increase (24%), while demand for tools needed to observe data will see a similar spike (22%) in 2026. There will be increased demand next year (19%) for data management tools that operate at the semantic level to provide a higher level of abstraction above the raw data stored in, for example, a data lake.
In comparison, demand for data integration tools and storage platforms will grow at slower rates of 12% and 11%, respectively, in 2026. However, as the volume of data being generated using AI tools continues to increase, the data storage platform market will be growing at a rate of 18% by 2030, according to the report.
As those investments are made, the role of the IT teams that manage data will also fundamentally change as more extract, transform and load (ETL) pipelines are created, also known as Zero-ETL. In effect, data engineering teams are evolving into shepherds of data that is increasingly being used to drive AI applications and agents.
Obviously, it’s still early days as far as operationalizing AI at scale is concerned, but the one thing that is clear is that legacy approaches to data management need to evolve. Most of them were designed around batch-oriented workflows that are increasingly being replaced by workflows based on data streaming platforms that are better able to support applications that need to consume and analyze data in near real-time. That doesn’t mean batch-oriented workflows will entirely disappear but it does mean that the way data is processed and managed will become a lot more nuanced.