
Securiti today revealed it has allied with Databricks, a provider of data lake, to better secure generative artificial intelligence (AI) applications and platforms.
Organizations building AI applications using data that resides in the Databricks platform will now be able to take advantage of the Gencore AI platform that is based on a data security posture management (DSPM) based on graph technologies developed by Securiti.
That capability will make it simpler for organizations to curate and sanitize pipelines created using the Databrick platform to ensure that the data being exposed to AI models and agents meets security, privacy and compliance requirements, says Securiti CEO Rehan Jalil.
That capability is integrated with Mosaic AI, a machine learning operations (MLOps) platform that Databricks added to a data lake it provides that is based on the open-source Apache Spark framework and the Delta table format that Databricks uses to store data.
That approach makes it possible to also apply entitlement controls to AI models and applications in addition to firewalls that monitor interactions with multiple large language models, otherwise known as LLM firewalling.
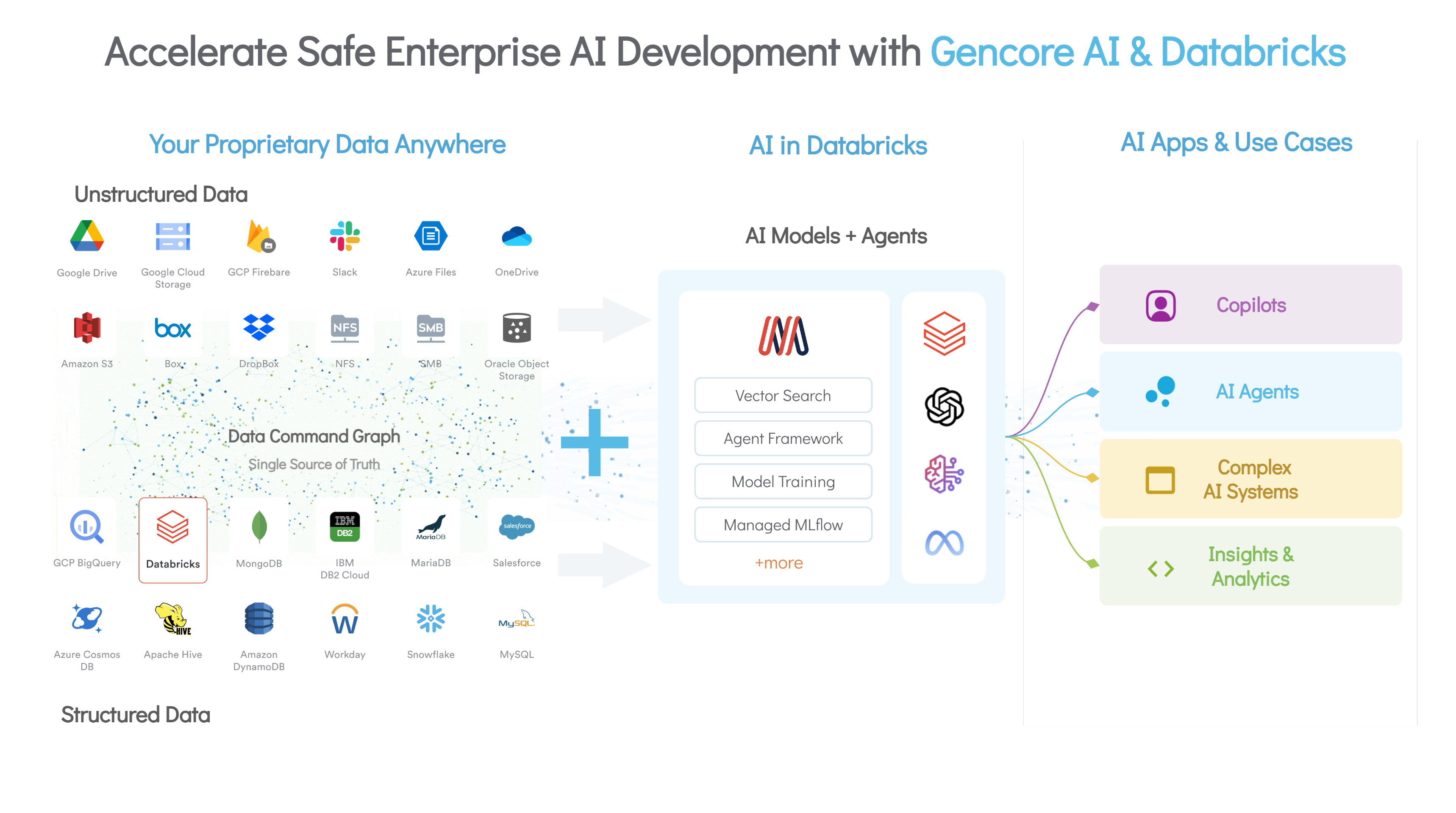
As organizations seek to operationalize AI in enterprise IT environments, they need a more holistic approach to security, that, in addition to protecting data and pipelines, also enables them to track the provenance of the data that has been exposed to any AI model at any given point in time, says Jalil.
The challenge is the data being exposed to AI models is highly fluid as organizations move to extend the capabilities of AI models by exposing them to additional data, he adds. “The data is always changing,” says Jalil.
The Gencore AI platform reduces that complexity by leveraging graph technologies to not only track the relationship between data sets but also apply policies that prevent, for example, sensitive personally identifiable information from being exposed to an AI model, adds Jalil.
It’s not clear to what degree data security and compliance issues are holding back the development of AI models and applications, but it’s only a matter of time before increasing concerns about transparency will require more organizations to be able to precisely show how an AI model was trained. Inevitably, there will be lawsuits that will require organizations to conclusively show that an AI model was not deliberately weighted to favor one potential outcome versus another.
The challenge organizations face today is making sure the safety and provenance controls that will be required are embedded into applications before they are deployed in a production environment. Many organizations today are experimenting with AI applications without considering the need for those controls until after the AI application has been created using data that might not have been thoroughly vetted. As a result, the probability there will be issues in the future involving how and why certain data sets were selected to train an AI model is high.
None of that necessarily means the pace at which AI applications are being developed needs to slow down, but it does mean that in the rush to not be left behind, there is still a need for considerably more prudence.