
As you already know, there is no perfect model to cover any content in a certain niche. To make the right choice, you need to run tests for every project, language pair and even every type of content (such as marketing, UI and website).
This approach helps save money — it’s like testing a minimum viable product (MVP) instead of going all out with risks of poor results.
But how should you run tests and evaluate the results? In this article, we’ll share our behind-the-scenes process. You’ll learn:
- What top models do we use for testing
- How the testing process goes
- What metrics are included, and why they are not equally important
- Our secret tool to avoid bias in evaluation
- Why can’t you choose a model once and for all (a real-life example)
There are Various Models. Which Ones do You Use for Tests?
Yes, there are dozens of neural machine translation (NMT) and large language models (LLMs) on the market. We stick to the top industry ones and constantly keep an eye on new promising models — recently we’ve added DeepSeek and Grok (x.ai).
Below are our most popular NMT and LLM models based on the stats for the past six months. This infographic includes only those models that were chosen as best-performing for Alconost’s AI translation projects. The higher the percentage, the more often the model gets selected.
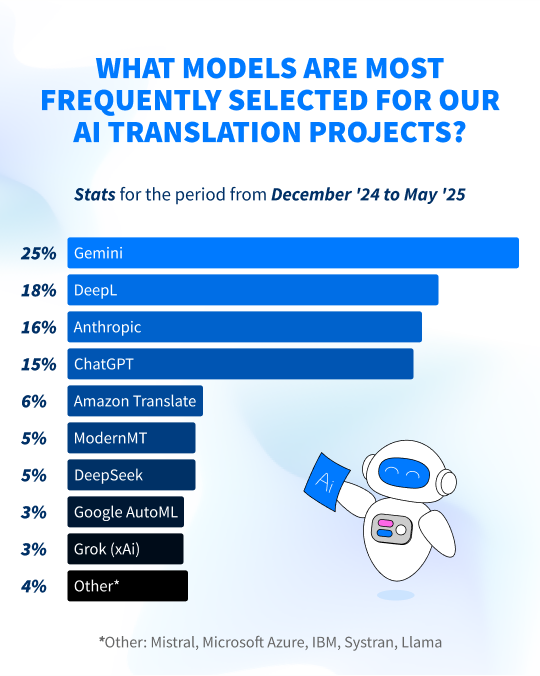
Why not just take those four top performers from this list and only use them? Well, the above figures are valid as of May 2025, but they are not set in stone. In this industry, experimenting and testing are important to keep up with the constant changes.
For example, the new Grok model brought us a surprise on the testing stage for one of our new projects: It outscored all regular top performers for such a common language as German. Below are consolidated testing results for this project:

Such cases are hard to predict as models evolve, and each project has a unique combination of domain and content type and, of course, client requirements. However, there is one thing repeating our stats: LLM models tend to outperform NMTs.
Testing Process Step-by-Step
Step 1
We carefully review the source content and client requirements and develop a tailored prompt. Then we run a sample text (~1500–2000 characters) out of the client project through all the chosen models into all the target languages.
We compose a sample text out of different parts of the source content to accurately reflect the nature of the client’s project. Strings with variables and code should also be included to see how well models can process them. In case the client project consists of several different types of content, we’ll test them separately to get accurate results from testing.
Step 2
The linguists for the required language pairs evaluate each machine translation (MT) version and leave comments and scores.
Step 3
They post-edit the best version, which becomes the reference translation.
The results of testing and linguistic evaluation are exported to a spreadsheet. See the image below for a shortened version of the test for Spanish (ES).
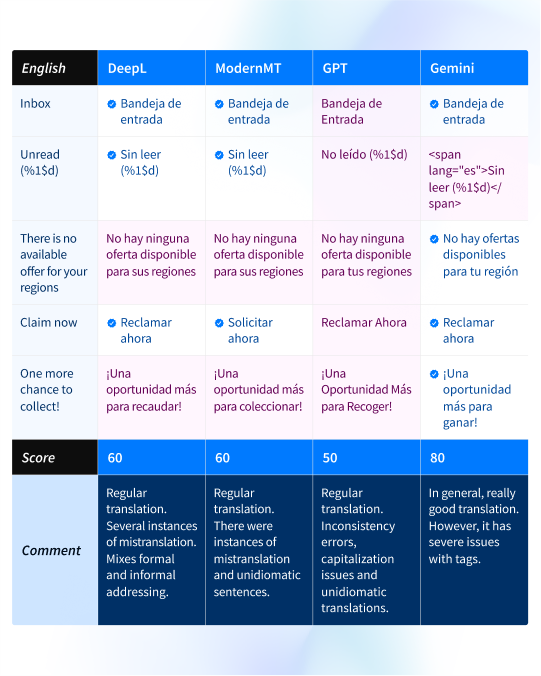
Score refers to the linguist’s evaluation metric and ranges from 10 to 100.
Step 4
Once the reference translations are ready, we upload them along with the raw MT versions to a special tool to get the metric scores. The tool compares the raw MT versions against the post-edited version (reference translation). Here is an example of exported results:
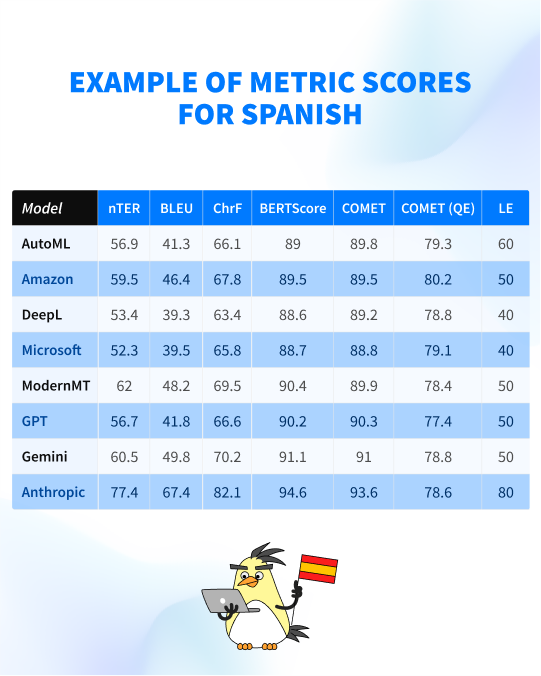
The goal of the metrics is to assess quality (grammar, fluency, mistranslations, usage of tags and placeholders, etc.) and measure the post-editing efforts required to achieve the desired level of quality.
The desired level of quality is discussed with the client during the pre-testing stage. Non-critical content (help desk materials, internal presentations, etc.) allows more flexibility and may need less post-editing (or even none).
We always take time to instruct our linguists before they start post-editing. They receive a style guide and post-editing guidelines about what type of errors are critical for this project and what can be ignored.
To sum up, running the tests looks like below

Following the evaluation, the client receives a comprehensive report:
- 10+ translation versions from various NMTs and LLMs
- A review of each version by a professional native translator, including a score and comments
- A list of top-performing AI models with performance metrics
- A final Alconost Quality Index (AQI) score that consolidates all these results (more on that further down)
- A list of rates per language based on evaluation results
What Metrics are Used for Testing?
There are over 100 metrics suggested by researchers, and they all evaluate different aspects of MT. Some of them are created to evaluate LLM translations (and not NMT), some focus on fluency assessment, others on precision.
Most metrics are reference-based: They are used to evaluate how well MT text matches a human reference translation of the same source content.

Reference-free metrics don’t need a reference translation and are used to further cut costs and speed up the process. We also use one of these metrics in our work. However, such metrics are less reliable than reference-based metrics and serve more as guidelines.
To get a comprehensive view of each model’s performance, we at Alconost put together a versatile set of top industry metrics. Combined with a human evaluation score, this approach ensures an objective, bias-free scoring system.
Reference-based metrics we use:
- COMET QE leverages information from both the source input and the reference translation and shows good correlation with human judgement.
- BERTscore uses a context-aware approach to compare the similarity of the MT output and the reference translation.
- Bilingual evaluation understudy (BLEU) is based on sentence-to-sentence comparison. It calculates how many n-grams (a sequence of characters or words) in the MT translation match the reference.
- nTER indicates the level of human effort required for post-editing. It’s crucial for understanding cost and time efficiency in machine translation post-editing (MTPE) workflows.
- CHrf++ provides useful complementary insights for certain language types (such as morphologically complex languages) where word-level metrics fall short.
Reference-free metric we use:
- COMET QE offers critical error detection and explainable quality estimation. For this metric, we use the COMET QEKiwi22 model that is trained on direct assessments and multi-dimensional quality metrics (MQM) annotations and supports sentence- and word-level quality predictions.
COMET QE is important for real-time applications or when references are unavailable. However, it’s biased: It focuses on fluency and may ignore grammar. Sometimes we see that the score by a human translator/post-editor is only 20, while COMET QE gives a score of around 70–80.
Getting Over the Shortcomings of QE Metrics
The problem with quality evaluation metrics is that they have their weaknesses or biases. For example, nTER does not capture fluency, and BLEU doesn’t consider grammar and sentence structure.
These metrics were created with different focuses, so they all bear a different weight (impact). If these scores are not equal in importance, it’s hard to make a final judgment about the model’s performance.
We’ve been experimenting with ranging metrics based on their impact and developed our own reliable unified benchmark — AQI.
AQI is a comprehensive metric that synthesizes various automated and human evaluation methods to deliver an overall assessment of translation quality. AQI ranges from 0 to 100.
Once we receive all the scores, we run them through our tool to calculate the final score, AQI. It lets us understand the overall quality of the output at a glance:
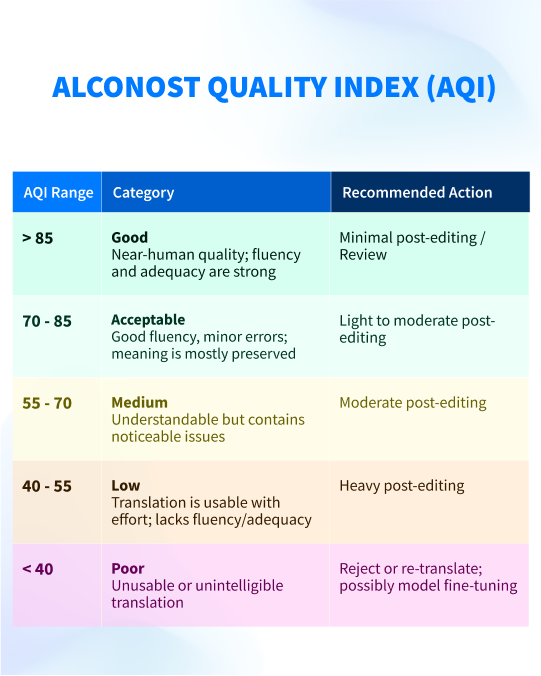
AQI gives us a quick and easily accessible interpretation of all metrics, along with the linguistic evaluation. Most importantly, it’s an objective interpretation.
It happens that models such as GPT and Gemini suddenly drop their performance — for example, they start processing strings with variables in a weird way. In this case, we turn to the test results, and AQI helps us quickly find an alternative model for replacement.
One Model to Handle all Language Pairs?
There is a common misconception that you can pick one top-performing model once and for everything. Unfortunately, it’s not that simple, and here is why:
- A single model can’t handle all language pairs with equal results. Some excel at European languages but fail at Chinese; others can handle Arabic well but struggle with easier languages.
- The combination of language and domain matters. A model may handle Spanish with ease but struggle when it comes to a combination of Spanish and a specific domain, such as cryptocurrency or agriculture.
- Models get constantly updated, and their performance may change. It’s important to keep testing and experimenting to get the best output possible.
A recent example: Evaluation of a website blog translation project showed that each language performed best with a different NMT or LLM model. For this project, we chose a mix of models, including DeepL, Gemini, ChatGPT, DeepSeek and Grok. Interestingly, each of the top-performing models achieved the highest scores in at least one language, while all the other models consistently lagged.
For projects with many languages, we often must choose several models to maximize the quality for every language pair. But even then, the choice may not be final.
Here is a real-life example:
When we implemented MTPE for Vizor, a popular game developer and publisher, there were 11 languages. Initially, all these languages were translated by Alconost’s native-speaking linguists.
We did the tests and showed the results to the client. They decided to switch to MTPE for nine languages, keeping the two most important ones for native-speaker localization.
For these nine languages, two models were chosen: ChatGPT and DeepL. Every three months, we did new tests to track AI performance and improve the output, and here is what happened:
- At one point, the latest version of ChatGPT came out.
- Our tests showed that ChatGPT outperformed DeepL, so it replaced DeepL for all languages except Korean.
- A new version of Gemini — a new round of tests — and we found out that Gemini became the absolute leader in all language pairs (in the project).
That’s why we do regular testing for all continuous projects. Regular linguistic quality assurance (LQA) cycles are necessary if you want to maintain consistently high quality, but that’s a topic for a different article.