
Here’s a pop quiz for you: For companies building out new AI data centers, what’s the biggest barrier to profitability? The options are a) overhyped demand for AI, b) high costs of graphics processing units (GPUs) or c) inefficient network infrastructures?
If you chose the first, think again. Market demand for AI applications shows no sign of slowing down. One 2024 survey found that 43% large enterprises already use generative AI (GenAI) and 46% use large language models (LLMs). Gartner estimates that spending on AI software will reach nearly $300 billion by 2027, with an exceptional compound annual growth rate (CAGR) of 19.1%.
If you picked option b), operators are indeed investing billions into high-end servers, GPUs, and other accelerators (xPUs) to support ever-larger AI models. But as customer demand explodes, they are getting more concerned with making sure they can meet it. As Alphabet CEO Sundar Pichai told investors last July, “In technology, when you’re going through transitions [like AI], the risk of underinvesting is dramatically greater than overinvesting.”
Believe it or not, the biggest obstacle to AI data center profitability right now is the networks connecting those specialized processors and accelerators. An under-appreciated reality of AI clusters is that, at a scale of tens of thousands— and soon hundreds of thousands— of xPUs, you’re inherently building distributed computing systems. Since no single node can process the entire model, the network interconnecting them effectively is the computer. If it can’t keep up with AI workloads, those expensive xPUs can end up spending up to a third of their operational life sitting idle.
Underutilized resources at this scale represent more than lost opportunity. They’re a huge hit to return on investment (ROI) — a factor that will likely differentiate successful AI deployments from those that fail to scale.
Fortunately, thanks to new networking architectures, ongoing Ethernet advances and improved tools for testing and validating AI fabric designs, the industry is making big strides in addressing this problem.
A Need for Speed and Performance
AI clusters are not like traditional data centers. To meet the extreme demands of AI model-training and inferencing workloads, operators increasingly use dedicated, scalable and routable back-end networks to connect distributed servers and storage, often in spine-leaf architectures. These networking fabrics must support:
- Complex AI models with billions—soon trillions—of dense parameters
- Data- and compute-intensive workloads with bursty, unpredictable traffic patterns
- Thousands of jobs running in parallel, in perfect synchronization
- Network bandwidth of 1 Tbps per accelerator or higher
Critically, AI networks must provide extremely low latency and lossless performance across thousands of nodes. Job completion time (JCT) is typically the most important performance metric in AI, and unlike with conventional workloads, packet loss in one node can grind jobs to a halt while every other node waits.
To provide effective AI processing—and maximize the high cost of data center investments—back-end networks should operate at close to 100% utilization. Achieving this level of lossless performance is no small task. Most early back-end networks primarily relied on proprietary InfiniBand technology for this reason, although Ethernet is rapidly evolving to meet the demand as well. Today, operators are increasingly adopting 400G and 800G Ethernet ( with 1.6T on the horizon), leveraging RDMA over Converged Ethernet version 2 (RoCEv2) protocol to achieve comparable performance while using a familiar and standardized mass-market technology.
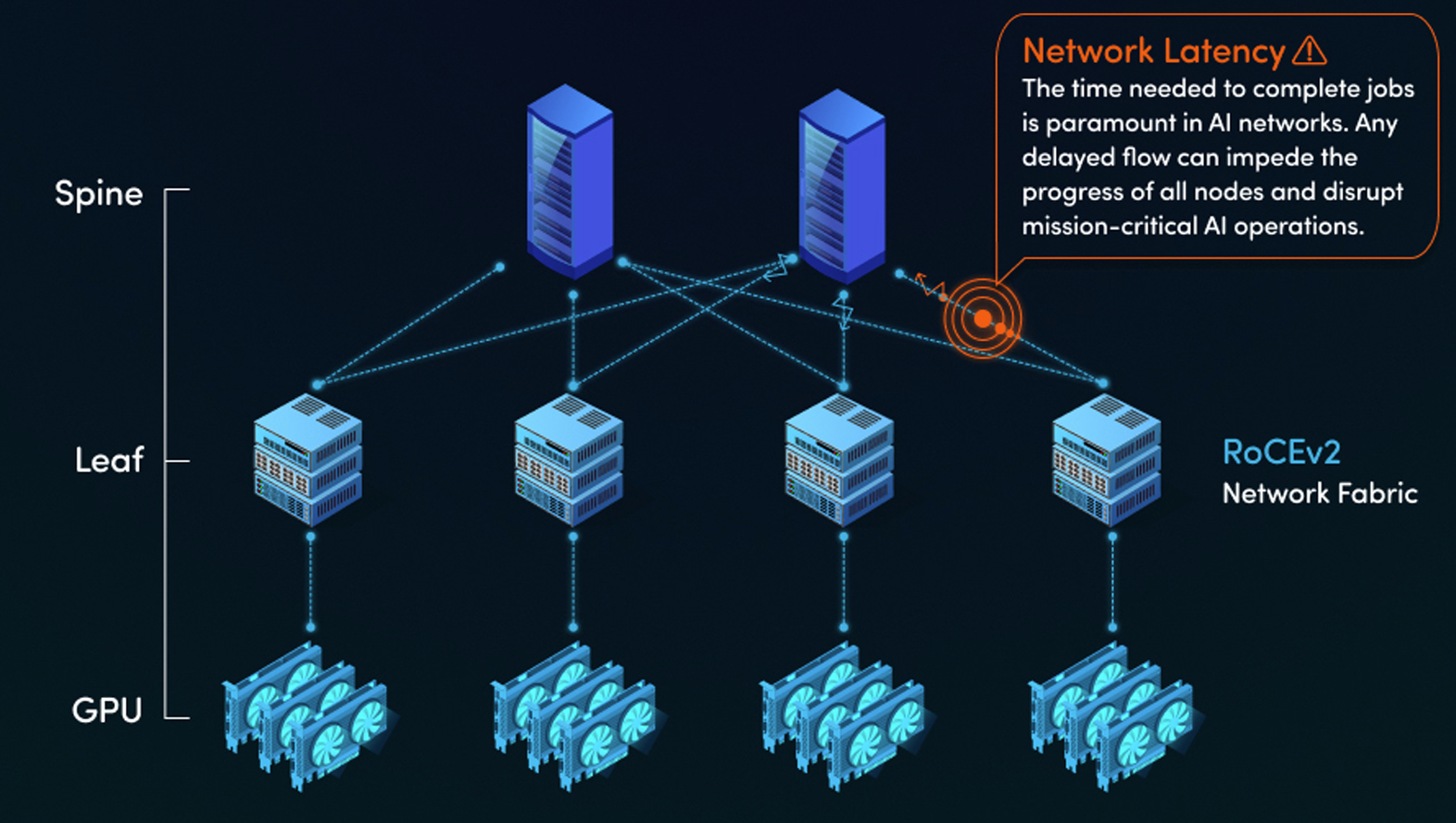
Figure 1. AI Networks Need Lossless Performance
The Cost of Inefficiency
Just how much does poor network performance cost AI data centers? Even more than it might initially seem. Given the need for tight synchronization across nodes, packet loss of just 1% can be equate to 33% lower AI training performance, and even greater reductions in xPU utilization. (Meta reported that in their initial AI clusters, a third of the time was spent waiting on the network.)
But what does that mean for ROI? Dell’Oro Group recently shared an economic analysis.
Figure 2 provides a hypothetical 4-year cost comparison for an AI investment. On the left, one organization invests $1 billion to build out its own AI infrastructure which operates with an average 1% packet loss. The organization on the right instead rents GPU-hours from another provider with a more efficient infrastructure. The right-hand organization has a higher outlay over four years ($2.5 billion compared to $1 billion), but they accomplish much more per GPU hour. Thanks almost entirely to better resource utilization and improved network performance, the right-hand organization sees hundreds of millions of dollars higher ROI.
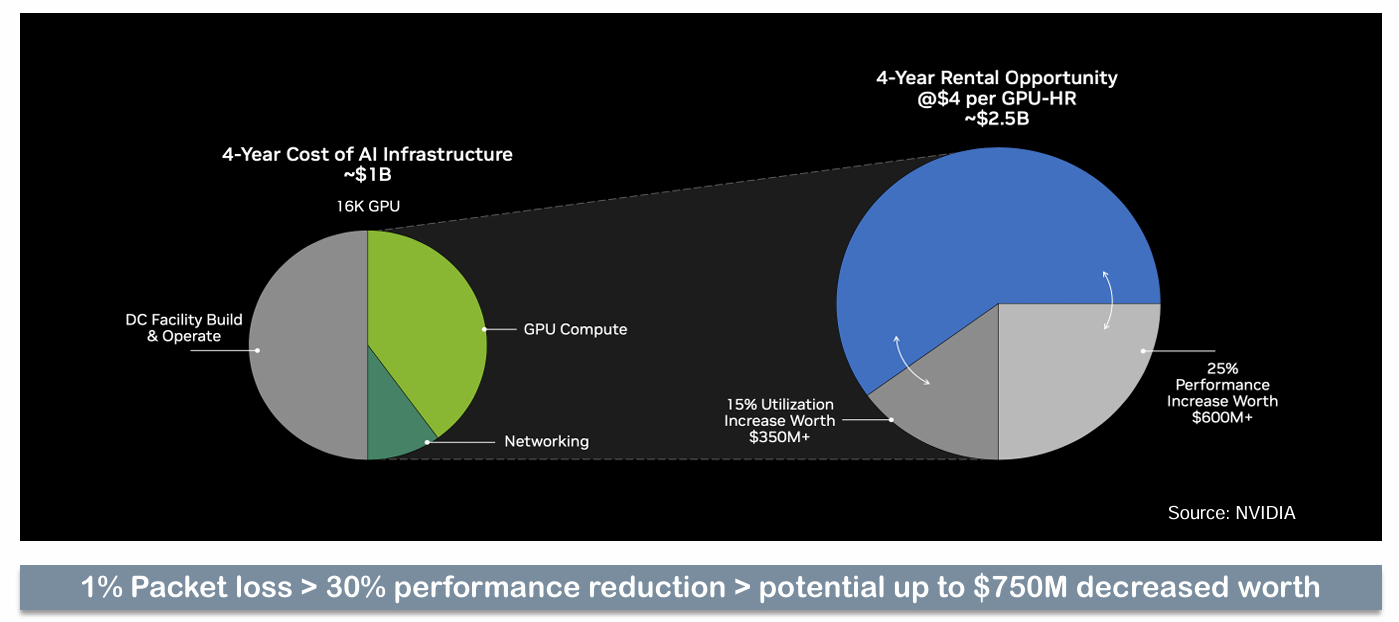
Figure 2. AI Infrastructure Cost Comparison
The Critical Role of Testing
Clearly, network efficiency is a make-or-break factor in AI data centers. Any organization operating one should be conducting ongoing testing and assurance to identify bottlenecks and continuously validate performance. And organizations planning new AI deployments should do everything possible to ensure that their infrastructure design will achieve the needed efficiency—ideally before they deploy.
Unfortunately, this is easier said than done. AI workloads are so different from conventional applications, and so sensitive to traffic congestion, latency, and loss, they’re basically impossible to emulate realistically with traditional testing. Additionally, it’s common for tests that look successful in small-scale, controlled environments to fail under the demands of live AI operations. Effectively, you need an AI infrastructure to test an AI infrastructure.
So how can organizations verify that a planned fabric design will actually hold up under real-world conditions before building it?
Fortunately, AI network testing is evolving alongside AI itself. New industry advances, like Collective Communications Library (CCL), enable organizations to inject realistic AI traffic patterns into test environments and use digital twins to test Ethernet fabrics in isolation. Using these AI-optimized testing approaches, organizations can:
- Mimic the behavior of AI worker nodes and processors, without having to buy and configure large server farms of expensive GPUs
- Simulate back-end Ethernet fabrics at scale, including simulating common congestion and resiliency scenarios
- Accurately emulate AI traffic patterns, such as AlltoAll, RingReduce, Broadcast, and others
- Measure a variety of network performance KPIs, including JCT, throughput, tail latency, packet latency, packet loss, and others
With these capabilities, organizations can validate AI networks earlier in the planning stages — often at much lower cost, with far less effort and specialized expertise than those building out full AI infrastructures for testing. They can thoroughly stress-test planned fabric designs before deployment instead of after. And they can ensure that, no matter where the AI market moves next, they’re realizing maximum value from their investments.