
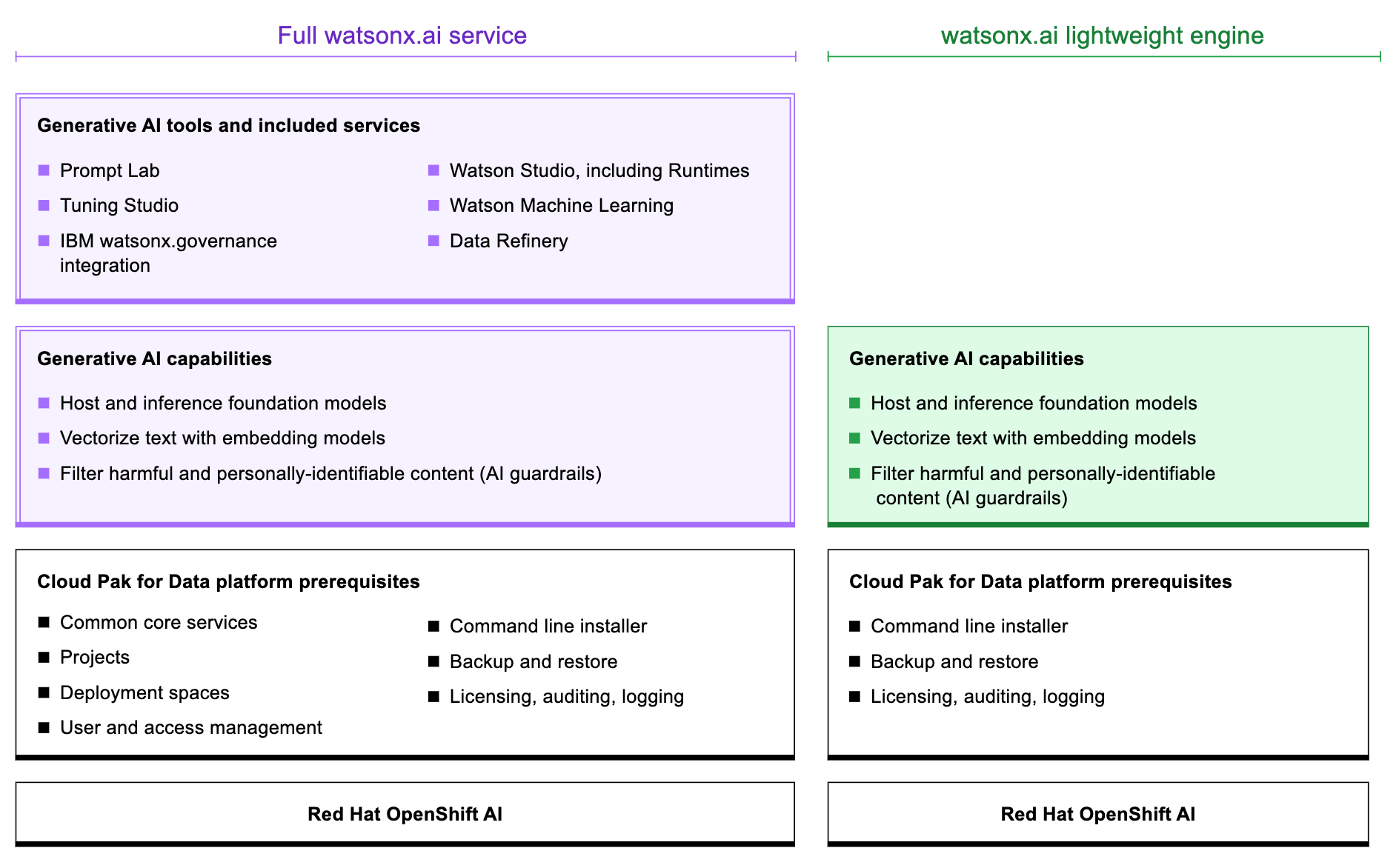
IBM has made available a framework that makes it possible for IT teams to deploy a lightweight instance of the inference engine it created for its watsonx.ai service in an on-premises IT environment.
That capability provides IT teams with more control over costs by eliminating the need to rely on a cloud service that charges organizations based on the number of input and outputs tokens consumed, says Savio Rodrigues, vice president for ecosystem engineering and developer advocacy for IBM. “Organizations want to be able to run an inference engine somewhere they control,” he adds.
That option will enable, in some cases, an IT team to significantly reduce the total cost of AI, notes Rodrigues.
The toolkit includes application programming interfaces (API) for inferencing foundation models and vectorizing text programmatically, guardrails for filtering personally identifiable information along with content involving hatred, abuse and profanity, the Cloud Pak Data platform for managing installation, auditing, licensing, logging and an instance of the Red Hat OpenShift AI platform based on Kubernetes.
As enterprise IT organizations start to build their own generative AI applications, many of them are relying on existing IT teams to deploy inference engines. That approach enables data science teams to focus more of their time and effort on training AI models versus deploying them.
Most of those inference engines are measured in terabytes, so in that sense they are simply another artifact that, for example, a DevOps team could deploy.
Additionally, IT teams gain control over what type of processors to use to run those models. In some cases, that might be a lower cost graphical processor unit (GPU) or, alternatively, a less expensive class of processors that might be more readily available.
Regardless of approach, there is already significant pressure to rightsize AI inference models as they look to determine which AI projects to prioritize based on the funding available. Organizations in more recent times are more sensitive to the cost of IT. In fact, many have repatriated other classes of workloads from the cloud back into on-premises IT environments to reduce costs. Exactly where an AI workload should run is now being more carefully scrutinized.
At the same time, there are still many organizations for compliance reasons that are not allowed to shift data into cloud computing environments, while others would simply rather ensure they retain control of their data.
Inevitably, there will soon be large numbers of AI models of varying sizes running either in a local data center or private cloud managed in an internal IT team. The issue now is determining which types of AI models lend themselves best for specific uses without breaking the proverbial IT budget.
In the meantime, IT teams should familiarize themselves with varying types of AI models and their underlying inference engines. There is after all, no substitute for training, because the first time an IT team deploys something should be part of a test, rather than as part of an application that is about to go live.