
Recently, we’ve seen a significant surge in the use of artificial intelligence (AI) and AI-powered tools and technologies in industries such as healthcare, finance, manufacturing and many more. Organizations should be able to optimize operational efficiency, be proactive and embrace AI and AI-powered technologies to drive business growth.
In this article, we’ll look at what data quality in AI is all about, why it matters, the risks of training AI models on bad data and the best practices to make your AI predictions accurate and reliable.
Understanding the Problem
Most AI projects are crippled by inconsistent, incomplete and biased data. For example, your data might be erroneous and inconsistent when multiple sources give conflicting information, and this can produce inaccurate predictions.
You must know that AI will only give you correct results if you feed it with ‘good data’. Here, the term good data implies data that is clean and reliable. You can use good data to build reliable, fair and efficient AI systems. On the contrary, ‘bad data’ — i.e., erroneous, inconsistent, unreliable and biased data — may introduce security vulnerabilities and yield incorrect results.
Hence, we should use high-quality data for our AI projects. Your organization can use data governance, data profiling and cleansing, data monitoring and validation and also follow certain best practices to eliminate data quality issues effectively and efficiently.
What is Data Quality? Why Does it Matter Anyway?
With AI everywhere around us, we should know what makes it so powerful and where it fails. One key factor is data quality, which denotes the degree or extent to which the data is suitable for use with AI.
Data quality is a combination of the following four key factors:
- Accuracy: This tells us whether the data is error-free. The data you use for training models must be accurate so that the predictions made based on this data are also accurate. If your data is inaccurate, either the model will not be reliable, or your model and subsequent analysis and predictions will not be trustworthy.
- Consistency: This helps us to know if the data is uniform. If your data is inconsistent, it will take a lot of time and effort to identify any missing fields in the dataset, duplicates and other types of inconsistencies.
- Completeness: Your data must be complete, i.e., you must have all the data your need before you use it for AI. When a model lacks access to all the necessary data, portions of its knowledge will inevitably be missing. Those missing portions will show up as biases, causing the model to behave poorly on instances that differ even slightly from its training.
- Relevance: If your model is not based on relevant data, training the model will be time-consuming, and you’ll have to incur expenditures in the usage of computational resources and time to train the model.
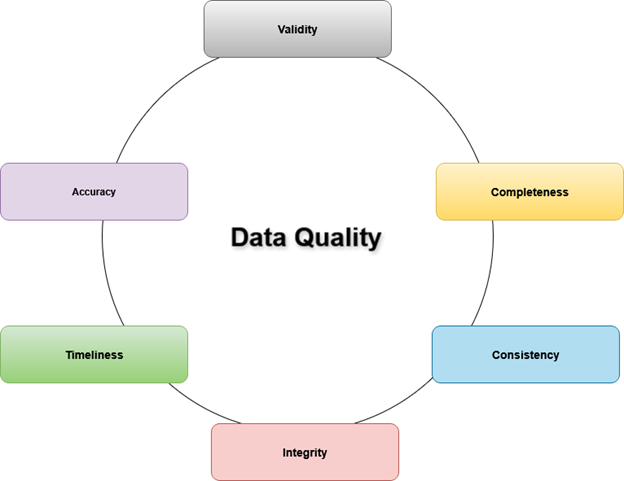
Figure 1: Demonstrating Key Factors of Data Quality
Best Practices
Here are a few recommended best practices you should follow to ensure that your data quality is of the highest standards and quality.
Data Cleansing and Profiling
Prior to using your data for AI, you must clean it to make it AI-ready. Data profiling and cleansing are the foundation of that readiness. The former is concerned with analyzing the data to understand how the data is organized, i.e., its structure, and also the data quality, to identify disparities, inconsistencies and anomalies in the data.
In other words, it is a process of systematically examining the structure of the data, the overall quality and overall integrity of the data as well as identifying irregularities and deviations. The latter is the activity of fixing or removing bad data from the dataset. However, even before you clean your data, you need to know how the data is structured.
Data Integration and ETL
The data you use for analysis and prediction is key to building good AI models. Data integration and extract, transform, load (ETL) are key to data quality. Some of the recommended practices include standardizing data formats, validating the data and handling errors that can occur at runtime. You must follow the recommended ETL practices to avoid data loss and corruption so that you only use high-quality data for your AI models.
Data Validation
Data validation is critical to ensure your data is meaningful, accurate and reliable. You must validate your data for quality issues against predefined criteria. You can take advantage of data observability platforms to automate this process, so as to gain real-time visibility into data quality. Ensure that you validate the data on a regular basis, i.e., it should be a continuous process, so you can always work with high-quality data.
Data Monitoring
You should monitor your data to catch data quality issues early and avoid downstream problems. You can use AI and machine learning (ML) to manage data quality in your organization. These can auto-detect and correct data anomalies, reduce manual effort and improve accuracy.
For example, you can use AI-powered data quality tools to identify patterns and trends in the data to help you manage data quality proactively. You must monitor your data regularly, i.e., it should not be a one-time activity. Instead, data monitoring should be a continuous process, so you can keep an eye on the data used for AI.
Data Quality
Besides following the best practices mentioned above, you should measure data quality as well. Quantify the quality of your data against certain key performance indicators (KPIs), such as accuracy, completeness, consistency and timeliness. You must define benchmarks for required KPIs and then measure the quality of your data against those benchmarks to ensure that the data quality is aligned with your expectations.
Conclusion
Today’s digital world thrives on data, and most businesses are using big data more than ever before. The blend of AI and big data has made data analysis easier by automating complex analytical tasks.
That said, data quality is key to building and training AI models, as it directly impacts the performance, accuracy and reliability of those models and AI-powered tools and technologies.
If the data used is incorrect, data analysis won’t be perfect either: The predictions made thereafter will be inaccurate. Hence, your organization must invest in data quality as a strategic decision that can drive innovation, better decision-making and business outcomes. If you’re able to adhere to the best practices outlined in this article, your data will be reliable, clean, meaningful and consistent.