
I’ve had the same conversation with at least a dozen companies this year. It often starts the same way: “We’re investing in AI.”
They spin up a team, pick a few high-impact use cases and start building. Maybe it’s a support bot. Maybe it’s an assistant for the finance team. The early demos look great. People get excited. Other teams want in.
Before long, three agents turn into 10. Then 20. At first, each one is a quick, self-contained build, just enough to get the job done. But there’s often no shared infrastructure, no real standards, and definitely no plan for how they’ll all work together. What started as fast progress turns into a disconnected mess.
Eventually, someone hits pause and says, “This is getting out of hand.”
That’s when the idea comes up: “What if we brought all these agents together into one system with a supervisor agent that could route requests and coordinate the rest?” The goal is to unify things. Instead of a bunch of scattered projects, you have a single multi-agent system. Sounds smart. Tidy. Centralized.
But now you’ve got a different problem.
You’ve traded a pile of scrappy one-off builds for one big, tightly-coupled system. It’s hard to test, harder to deploy and nearly impossible to scale cleanly.
The good news? We’ve solved this kind of problem before. We just need to remember how.
Let’s break it down.
Easy to Build But You Deployed a Monolith
When the sprawl starts to feel unmanageable, the natural instinct is to bring order. “We need a shared interface,” someone says. “Let’s create a supervisor agent to route everything.”
It sounds like the right move. Instead of every team building their own disconnected agents, you centralize coordination. Like an API gateway, the supervisor agent becomes the front door. It decides which agent to call, handles routing, shares context, manages access. You get consistency. Reuse. Control.
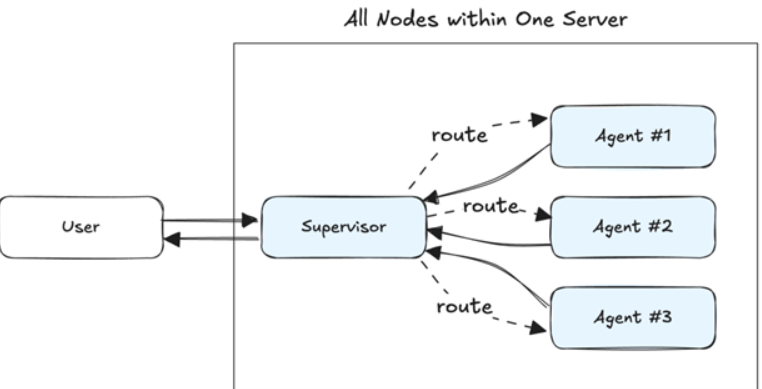
Example of the Supervisor Agent Pattern
(Credit Sean Falconer / Confluent)
Frameworks like LangGraph, CrewAI and others make this easy. They let you wire up multiple agents with explicit dependencies, create hierarchical routing logic, and build complex workflows. In short order, you can go from zero to a working multi-agent system.
But the ease of composition hides a deeper problem: None of these tools solve the infrastructure challenge.
All your agents now live in the same deployment unit. Maybe it started as one supervisor and three helpers but now it’s ten, then twenty, then more. Each use case might even become its own multi-agent system, and before you know it, you’re managing a huge, deeply nested graph of agents. And they’re all running in one big, tightly-coupled environment.
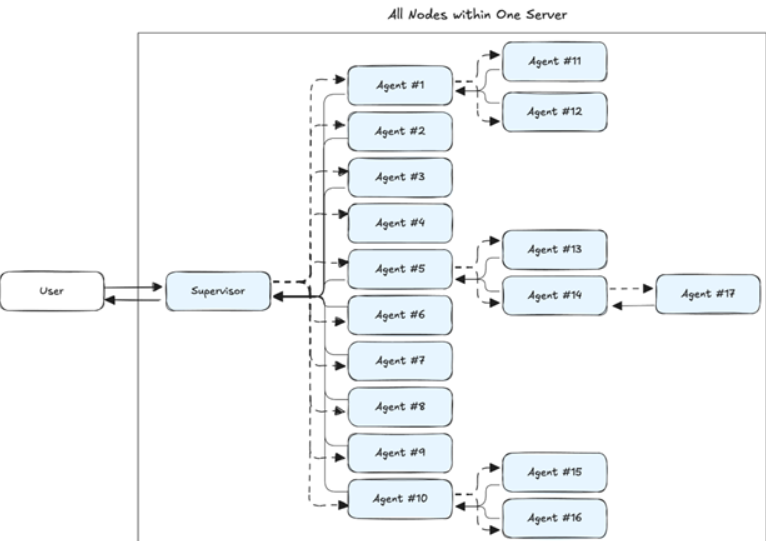
Agent Dependency Graph Quickly Growing Out of Control
Need to scale the support agent? Tough. It’s tied to the rest. Want to test changes to the HR agent? Careful, you might break everything else.
What started as an effort to clean things up ends up as a monolith in disguise. A smarter one, maybe. But just as brittle.
The Real Problem: We Forgot the Lessons of Software Engineering
This isn’t a new problem. We’ve just seen it take on a new form.
Back in the early 2000s, most companies were running big, monolithic applications. All the logic was packed into one giant codebase. Every release was a fire drill. A small change in one corner could bring down the whole thing. Testing was painful. Deployments were risky. And scaling was a nightmare and sometimes infeasible.
Then came the shift to microservices.
We broke those big apps into smaller, independent services. Each one owned by a team. Each one with clear contracts via APIs or events. You could deploy one without redeploying everything. You could test in isolation. You could scale what needed to scale. It wasn’t easy, but it worked. It let software grow without falling apart.
The same thing is playing out now with AI agents.
Right now, most companies are somewhere between agent sprawl and the monolith. They’re either drowning in disconnected builds or trying to glue them together into one massive system. Either way, it’s fragile.
But there’s a better way. We’ve just forgotten the map.
As Shantanu Ladhwe put it, “AI Engineering is still 90% real engineering.” And that’s the part we keep skipping.
Agents aren’t some special class of magic. They’re software. And they need to be built like it; modular, testable, scalable, and designed to change.
What the Future Looks Like: Agents as Microservices
Instead of piling all your agents into a single system, treat each one like what it really is: a microservice. Built independently. Deployed independently. Scaled independently. Owned by the team that knows the use case best.
In other words, agents should act like microservices with a brain.
I wrote more about this here, but the key idea is simple: If you want agents to be reliable and adaptable, they need to be part of a loosely coupled, event-driven system. Not a giant orchestration blob.
So what does that actually look like?
Going back to our earlier example, you don’t have to throw out the idea of a supervisor agent. You just need to rethink how it fits into the system.
Instead of one big process that contains every agent, the supervisor and each dependent agent becomes its own service. The supervisor still decides what needs to happen, but instead of calling other agents directly, it emits events. Those events get picked up by downstream agents that are listening.
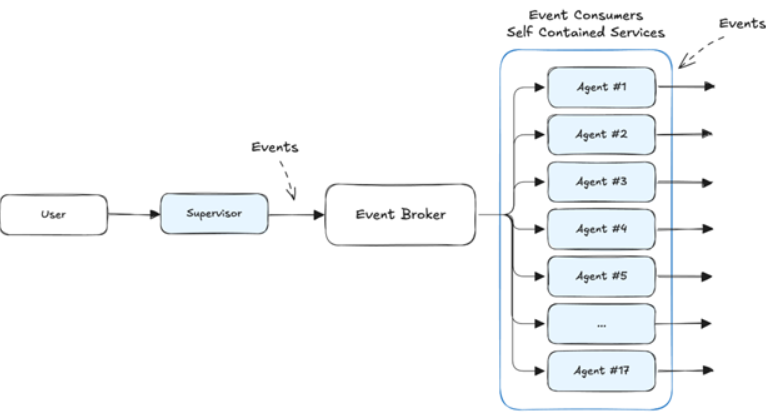
Agents as Independent Services and Producers and Consumers of Events
Let’s say the supervisor gets a customer support request. It emits an event saying, “New ticket received.” A ticket classifier agent, running in its own service, sees the event, processes it, and emits a new event with the priority level. That might trigger another agent to draft a response, or send a Slack alert, or kick off a follow-up task.
Each agent is doing its part, producing and consuming events, without being tightly coupled to the others. They’re composable, testable, and individually scalable. There’s no longer a quadratic explosion of dependencies, but a linear set of dependencies that’s loosely coupled and highly scalable.
This kind of thinking is what separates a flashy demo from a system that can actually run in production.
How to Break the Monolith (and Actually Make Progress)
You don’t need to rebuild your entire AI stack overnight.
The best way to move forward is to start small, pick one use case that’s relatively self-contained and untangle it from the rest. Define clear event contracts: what does this agent listen for? What does it emit? Then treat it like a real service. Add retries. Handle timeouts. Manage state where needed. Make sure it can fail gracefully and recover.
If you’re already using something like LangGraph, CrewAI, Autogen, or some other framework, you can still apply the same principles. This doesn’t have to be about switching tools. It’s about changing how you think about deployment, ownership, and communication between agents.
Move from function calls to events. Loosen the coupling. Let agents operate on their own timelines.
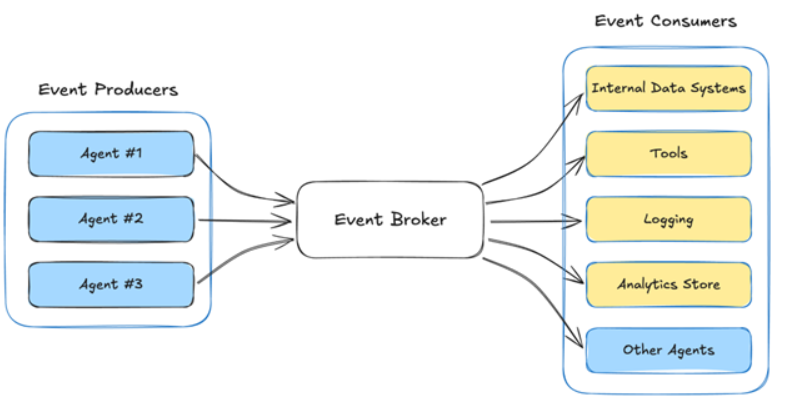
De-coupling Your Agent Infrastructure
(Credit Sean Falconer / Confluent all images/graphs)
Yes, this might seem like more work upfront. And if you only have a handful of agents, it might be tempting (or even fine) to keep them bundled together. But if history taught us anything, it’s that the monolith always becomes more work over time. That’s why we broke up our apps into microservices. The same logic applies here.
Start small, build the muscle and do it in pieces.
The payoff is worth it.