

Recently I attended the second AI Infrastructure Day event organized by the Tech Field Day team in Silicon Valley, where our delegate team spent the entire first day at Google Moffett Park Campus, which is a very inspiring venue, even without the content that was shared with us throughout the day on what Google can do for you and your AI applications.
One of the sessions that I highlighted in my agenda was the deep dive on what was announced at Google Next just a few weeks earlier: Google Cloud Managed Lustre, in partnership with DDN EXAScaler.

The Lustre parallel file system enables Google Cloud to offer file storage and fast access services for enterprises and startups building AI, GenAI, and HPC applications. It provides up to 1 TB/s throughput and can scale from terabytes to petabytes guaranteeing a latency of sub 1ms..
Key features include persistence, co-located deployment with compute resources, integration with Google Cloud services like Google Compute Engine (GCE) and Google Kubernetes Engine (GKE), and tuning capabilities based on customer workloads for optimal performance. Lustre offers a 99.9% availability SLA within a single zone but does not support multi-zone automatic failover, requiring architectures that back up checkpoints to Google Cloud Storage (GCS), which offers greater durability and multi-regional availability.
Hold on: Lustre you Said? What was that Again?
Lustre is a well-established parallel file system widely used on-premises, and Google Cloud’s offering aims to make it easier for customers to migrate to the cloud without needing to re-architect their workloads. The service leverages a collaboration with DDN, a leader in scalable storage, offering Google’s customers a proven, fully managed solution that scales from terabytes to petabytes with the highest performance required for AI/ML pipelines.
For the techies: Lustre is an object-based file system that splits metadata from the data and stores the metadata on the Metadata Servers (MDS) and the actual data in multiple objects on the Object Storage Servers (OSS). When a client opens a file, Lustre gets the access permissions & other pertinent metadata from the MDS, and after that all the I/O happens between the client and the OSTs (object storage targets). This is unlike other file systems which require going thru a single head node. Lustre allows multiple clients to access multiple OSS nodes at the same time independent of one another, thereby allowing the aggregate system to scale throughput by adding additional nodes in parallel.
Lustre also excels in synchronous checkpointing during long-running model training, writing data up to 15 times faster than competing storage solutions, thereby reducing the time GPUs spend idle. Support for Nvidia GPU Direct Storage means data transfers can bypass CPUs, reducing overhead, saving time, and lowering costs. Additional optimizations such as distributed namespace, file-level redundancy, and POSIX compliance ensure compatibility with existing AI workflows, enabling easy migration without the need to rewrite applications.
Further, when training tasks span days or even weeks, the demands of checkpointing – quite literally, copying the entire state of a GenAI cluster so the work already done can be restarted should a failure occur at any part of the cluster – means that every compute node’s filesystems and their contents must be copied repetitively and frequently. A Parallel File System like Lustre is a key solution in these situations.
Why Does Google Need this in its Portfolio?
One reason that solutions like Lustre have come to the forefront are the radically different demands of GenAI workload activities. It’s already understood that training a LLM usually requires massive ingest of structured and unstructured data.
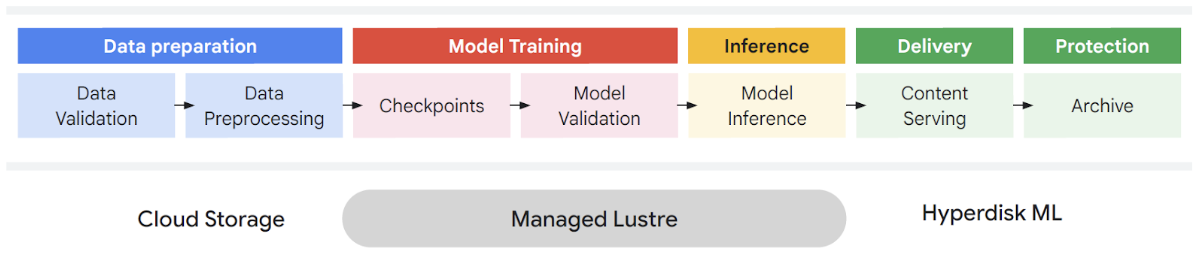
AI/ML Workloads have very unique demands on storage level.
These are characterized by phases including data preparation, model training, inference, and delivery. Each stage has distinct requirements:
- Data preparation can involve petabyte-scale datasets needing massive I/O bandwidth.
- Model training requires extremely high throughput to keep accelerators busy without idle time.
- Inference demands low latency for real-time predictions.
While certain storage solutions excel in a specific storage characteristic (for instance IOPS or throughput or latency), it is not always perfect in another one. This remains one of the challenges in the AI world where we see too many data sets on too many different storage platforms, on-premises or in the public cloud.
Managed Lustre targets the sweet spots in training and checkpointing by ensuring GPUs and TPUs are fully utilized, minimizing compute wait times caused by slow storage.
Managed Lustre is compatible with key Google Compute Engine (GCE) and Google Kubernetes Engine (GKE) environments, supporting containerized AI training workflows. Additionally, the service provides built-in APIs to perform batch data transfers to and from Google Cloud Storage (GCS), supporting checkpoint archival and restoring.
There is native support for Container Storage Interface (CSI) drivers, currently unmanaged with managed drivers forthcoming, enabling Kubernetes workloads to seamlessly use Lustre as backend storage.
Cluster management tools like SLURM are also supported by Google’s cluster toolkit. This facilitates scheduling and managing parallel jobs common in HPC and AI training environments, reducing the operational burden on customers.
Google provides a simplified console interface allowing users to provision Lustre storage by specifying region, capacity, and throughput, and deploy this file system to its various GKE and GCE instances to run the AI models.
Why is DDN in the Picture?
DDN EXAScaler accelerates AI, HPC, and data-intensive workloads with a high-performance, parallel file system that feeds GPUs at record speed. For instance NVIDIA uses these systems exclusively for their internal clusters as well, delivering extreme throughput and minimal latency for large-scale operations like AI training and HPC simulations—unlocking the full value of your compute investments.
DDN Lustre is a parallel file system known for its high scalability and performance, making it popular in scientific supercomputing and various industries like oil and gas, manufacturing, and finance. DDN offers various Lustre solutions like their EXAScaler appliances and so now as well as Managed Lustre offering on Google Cloud.
Integrating DDN’s mature EXAScaler product gives reliability in terms of performance and scaling, coupled with Google Cloud’s managed service model. This combination offers you an enterprise-grade performance with cloud-scale convenience.
Key Takeaways
- Google Cloud announces Managed Lustre, a fully managed parallel file system for AI/ML workloads.
- Designed to maximize GPU/TPU utilization with high throughput and low latency.
- Scales from terabytes to petabytes, delivering up to 1TB/s read throughput with sub-millisecond latency.
- Partnership with DDN leverages proven on-prem Lustre technology in a cloud-native form.
- Faster Checkpointing: Lustre enables synchronous checkpointing processes that are approximately 15 times faster than competing object storage solutions. This allows rapid and efficient saving of large model states during training, cutting down GPU wait times and recovery durations.
- Supports efficient synchronous checkpointing 15x faster than other storage options.
- Integrated with Google Cloud Storage for backup and higher durability beyond zone-limited availability.
- Offers seamless migration for on-prem HPC workloads due to POSIX compliance and metadata/data separation.
Conclusion
Google Cloud’s Managed Lustre offering fills a critical gap for AI/ML practitioners requiring scalable, high-throughput, and low-latency parallel storage. By partnering with DDN and delivering a fully managed experience, Google enables organizations to migrate demanding HPC and AI workloads from on-prem environments with confidence.
Traditionally, Lustre is powerful but difficult to manage, requiring specialized expertise. Google Cloud’s managed offering abstracts the complexity, letting customers request capacity and throughput targets without worrying about deployment details. This lowers barriers to adopting high-performance parallel storage at scale, allowing more teams to focus on innovation rather than infrastructure.
Interested in more Google presentations that we covered at AI Infrastructure Day 2? You can find it all at the Tech Field Day website!
https://techfieldday.com/appearance/google-cloud-presents-at-ai-infrastructure-field-day-2-2/