

Your data is your most valuable asset for AI, but it’s often locked away in different storage systems, clouds, and locations. How can you make all of it available for your AI workloads without undertaking a massive, costly, and disruptive migration project?
At the most recent AI Infrastructure Field Day event, Hammerspace presented its vision for solving this problem. Their approach isn’t about ripping and replacing your current infrastructure. Instead, it’s about creating a unified, intelligent data layer on top of it. Let’s dive into three key concepts they shared that could change how you think about your AI data strategy.
What is AI-Ready Storage?
Most companies have invested heavily in their storage infrastructure over many years. You might have NetApp filers for home directories, Isilon for large media files, and various object stores in the cloud for archives. This creates data silos, making it incredibly difficult to get a unified view of your data, let alone feed it all into an AI model.
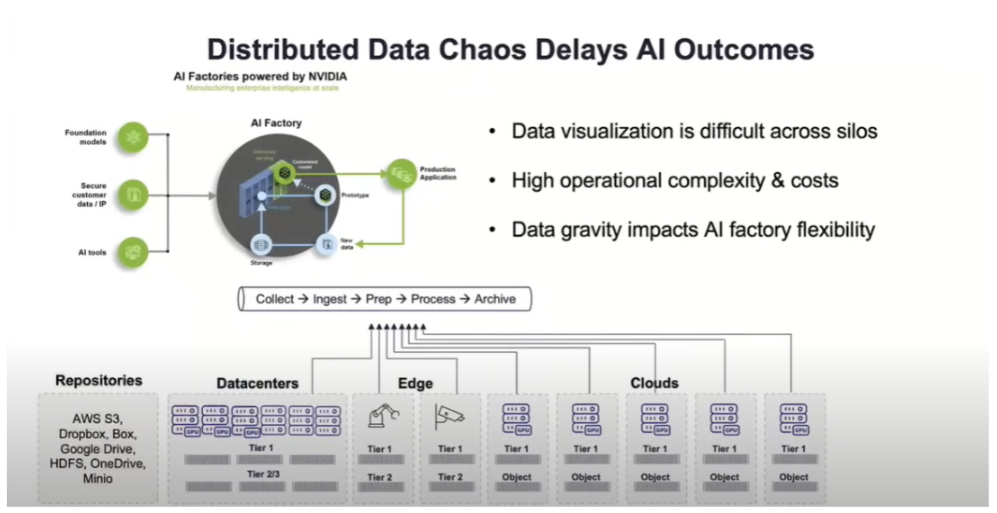
Hammerspace proposes a different path. Instead of forcing you to move all your data into a new, centralized AI storage system, they create a “virtual data layer” that sits on top of your existing infrastructure. This software-defined platform creates a single, global namespace. To users and applications, it looks like one massive, unified file system, even though the data physically remains in its original location, whether it is on-premises or in the cloud.
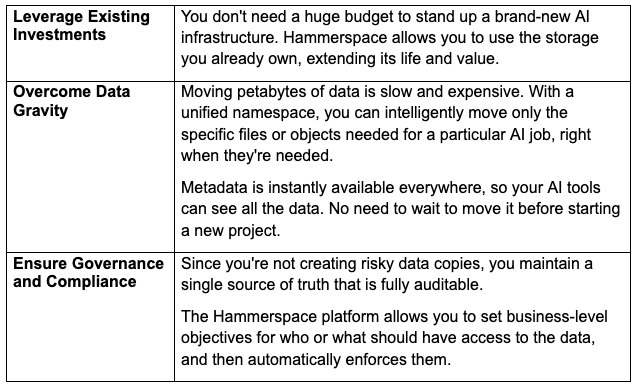
This approach makes your data AI-ready in several ways:
Activating Tier 0 Storage for Maximum Performance
Every modern server that is able to host GPUs also comes with high-speed local NVMe storage. The problem? This storage is usually stranded. The data on one server isn’t easily accessible to another, and the capacity sits underutilized. This means constantly pulling data over the network, and for demanding AI workloads like model training it becomes a major performance bottleneck.
This is where Hammerspace’s concept of “Tier 0” storage comes in. The platform uses its unique integration with the Linux kernel to aggregate all the local NVMe drives across a GPU or CPU cluster into a single, unified, and incredibly fast storage pool.
So instead of having dozens of small, isolated islands of performance, you now have one massive, high-speed continent of storage that all your GPUs can access directly.
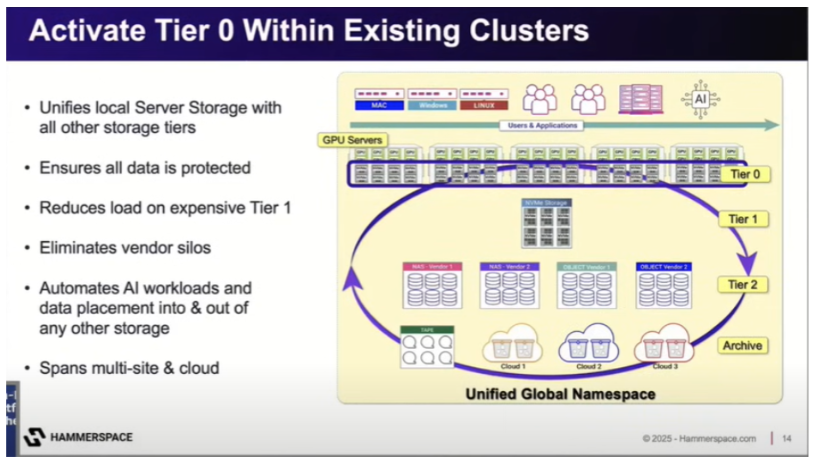
Using Tier 0 unlocks several key benefits:
- Dramatically Boost GPU Utilization: Making data available at local NVMe speeds ensures GPUs are constantly fed and utilized to their full potential.
- Reduce Network Bottlenecks: Data served from the local Tier 0 pool reduces reliance on east-west traffic across the storage network. This speeds up performance and reduces the need to invest in costly high-speed networking upgrades.
- Optimize Costs: You’ve already paid for the NVMe in your servers. Activating it as a shared Tier 0 resource is a sunk cost that you can now leverage to improve performance and reduce the need to buy expensive external all-flash arrays.
This standards-based approach is powerful because it doesn’t require installing proprietary agents on your servers. The necessary intelligence is built into the Linux kernel itself, a long-term investment by Hammerspace that pays dividends in simplicity and performance.
The Open Flash Platform: A Vision for Future AI Storage
Looking ahead, data requirements for AI will only grow. We’ll need to store and access exabytes of data efficiently, and current storage server designs are often too costly in terms of power, cooling, and physical space. To address this, Hammerspace is spearheading the Open Flash Platform (OFP) initiative.
The OFP is an industry collaboration to create a non-proprietary, standards-based storage platform designed for massive capacity and efficiency. The core idea is to move away from traditional, power-hungry storage servers and toward a much denser, more modular architecture.
Here’s the basic concept:
- High-Density Design: The platform is built around small, modular “sleds” containing a DPU (Data Processing Unit), networking, and high-density QLC or PLC flash storage. This design replaces an entire storage server in a fraction of the space and with significantly less power.
- Exabyte-Scale in a Rack: The ultimate goal is to enable the deployment of an exabyte of storage within a single rack. This density is a significant change for building out large-scale AI data lakes and archives.
- Standards-Based and Non-Proprietary: Unlike proprietary flash systems, the OFP is being developed as an open standard, with the goal of eventual adoption by bodies like the Open Compute Project (OCP). This ensures a competitive, multi-vendor ecosystem, driving down costs and preventing vendor lock-in.

For Hammerspace, the OFP is a natural fit. Because their software can run on a DPU and uses the standard Linux kernel, they can manage an OFP system with maximum efficiency, eliminating the need for separate storage head nodes. This initiative represents a forward-looking vision for how the industry can collaboratively build the foundational infrastructure needed for the next generation of AI.
Get Your Data Ready for What’s Next
The message from Hammerspace is clear: the path to successful AI adoption runs through your data. By providing a software-defined platform that unifies existing infrastructure, activates hidden performance, and paves the way for future hardware standards, Hammerspace is tackling the core data challenges that hold so many AI projects back. It’s an invitation to stop thinking about storage silos and start thinking about a unified data plane for all your AI ambitions.
Learn more about Hammerspace by watching their presentations at AI Field Day 3.