
As enterprises accelerate AI adoption, a hard truth is emerging: AI is not a simple overlay that will automatically turn your data into agentically actionable insight. It is a stress test of your entire data architecture. In a recent report by Futurum Research, we explore why many organizations are struggling to scale AI initiatives despite strong investment and clear strategic intent.
The issue is not a lack of ambition but rather architectural fragility. Futurum Research shows that common barriers to AI success, such as poor data quality, scalability, governance gaps, and integration complexity, are not isolated problems. Nor are they problems that can be addressed in isolation for a single use case. They are symptoms of a deeper issue, namely a database layer that was never designed for the demands of modern AI workloads.
This is where many enterprises are encountering friction. For decades, companies looking to do more with data could simply throw more storage or compute resources at the problem. But AI changes that equation. It introduces continuous, data-intensive transactions that expose architectural inefficiencies, turning what once were manageable limitations into critical bottlenecks that can’t be solved by orthodox architectures or methodologies.
To explain, consider what’s happening under the hood when a company tries to move from a basic AI chatbot workflow to an autonomous, agentic AI system. In this situation, basic query tricks such as prompt caching will not accommodate what could be tens of thousands of autonomous agents pounding back-end systems with millions of complex, concurrent transactions. This kind of demand completely breaks traditional architectures because AI agents have to constantly retrieve context and reason across a messy cocktail of data formats (e.g., vector, JSON, graph, spatial, and traditional relational data), all at the exact same time.
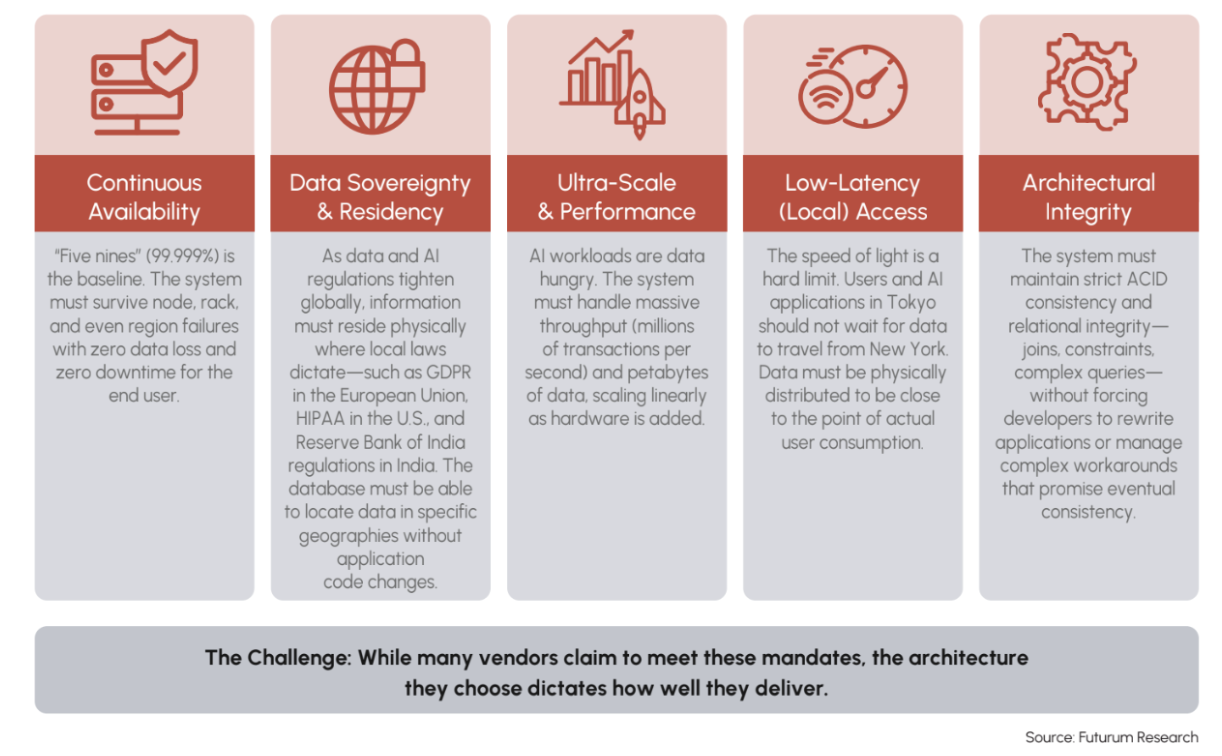
Today’s distributed databases need to meet this new baseline. Across all of these formats, agentic AI systems must simultaneously deliver continuous availability, ultra-scale performance, low-latency access, data sovereignty, and architectural integrity (see Figure 1). These are not optional features. They are interdependent requirements – if one falls, the rest falter. If a system compromises in any one area, it risks failing under real-world AI conditions.
Figure 1. Core Requirements for Distributed Databases in the AI Era
At the center of this evolution is a growing architectural divide with significant implications for enterprise decision-makers. The contrast in architectural philosophies between vendors such as Oracle and CockroachDB can serve as a useful lens for understanding this split.
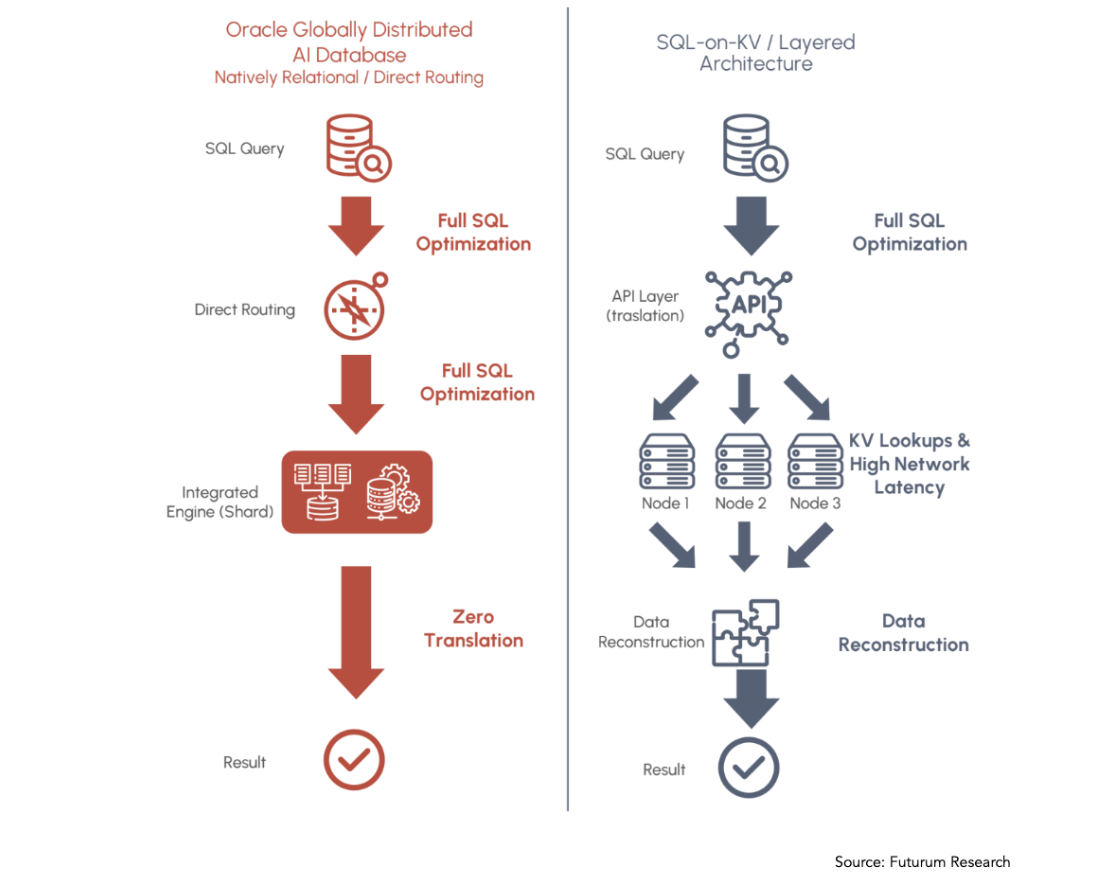
Oracle’s approach with its Globally Distributed AI Database is rooted in a natively relational, SQL-optimized data architecture that has been extended into a globally distributed model. This design preserves core database principles such as ACID consistency, relational integrity, and query optimization, all while enabling distribution at scale. In practice, it aims to run complex transactional and analytical workloads without introducing additional layers of translation or reconstruction.
CockroachDB, by contrast, follows a “SQL-on-KV” model. It layers an SQL interface on top of a distributed key-value store, prioritizing scalability and availability. This can deliver massive horizontal scalability, schema flexibility, and document-level concurrency without sacrificing must-have transactional reliability – a hefty lift for a NoSQL database. This can be very effective for certain use cases, such as e-commerce, where rendering very complex (polymorphic) data might require a large number of table joins in a traditional relational database. However, this approach entails some architectural trade-offs. Relational data must be decomposed into key-value pairs and then reassembled across nodes during query execution.
This distinction becomes critical at scale. For simple operations, the difference may be negligible. But as workloads become more complex, particularly in AI and analytics scenarios, the overhead associated with data reconstruction and network coordination can introduce latency and operational complexity (see Figure 2). This is what our report characterizes as a “reconstruction tax,” in which architectural costs can compound as data volumes and query complexity increase.
Figure 2. Native Relational Architecture vs. SQL-on-Key-Value Design
Beyond performance, architectural choices also influence how well platforms handle real-world enterprise requirements such as data sovereignty and global distribution. As regulatory environments become more complex, organizations need precise control over where data resides and how it moves. More flexible distribution models enable this level of control, while more rigid approaches can introduce trade-offs in compliance, performance, or operational simplicity.
These differences ultimately extend into analytics and AI. Modern AI applications require the ability to process large volumes of data in place, minimizing movement and enabling real-time insights. Architectures that depend heavily on moving and reconstructing data across nodes can struggle under these conditions, often requiring additional systems or data duplication to compensate.
The broader takeaway here is that database architecture is no longer just an infrastructure consideration of scale (add more storage, more compute). It is instead a strategic decision that directly impacts an organization’s ability to scale AI systems with unorthodox demands. Enterprises that prioritize architectural integrity, ensuring that performance, consistency, scalability, and flexibility are built into the underlying data foundation, will be better positioned to support the next generation of AI-driven applications. Those that do not may find themselves constrained not by ambition, but by the limits of their underlying systems.
For a deeper analysis of these architectural trade-offs and how they influence performance, scalability, and long-term AI success, read the full report here.