

Large language models (LLMs) have rapidly evolved from research curiosities to practical tools for a wide range of applications, from code generation to content creation. Running these models locally offers several advantages, including data privacy, reduced latency and the ability to operate in air-gapped environments. Ollama provides a straightforward way to run and manage open-source LLMs on your local machine. This post explores how Cloud Native Buildpacks can streamline the process of packaging and running Ollama.
-
What Are LLMs?
At their core, LLMs are deep learning models with a massive number of parameters, trained on vast datasets of text and code. These models leverage the transformer architecture to understand and generate human-like text. Key characteristics include the following:
- Transformer Architecture: This architecture excels at capturing long-range dependencies in sequential data, making it highly effective for natural language processing. Self-attention mechanisms allow the model to weigh the importance of different words in a sequence when processing them.
- Scale: LLMs often have billions or even trillions of parameters, enabling them to learn complex patterns and nuances in language.
- Generative Capabilities: Unlike discriminative models that classify or predict, LLMs can generate new text that is coherent and contextually relevant.
- Few-Shot Learning: Many modern LLMs exhibit the ability to perform new tasks with only a few examples provided in the prompt.
Examples of popular LLM architectures include GPT, Llama and the various open-source models available on platforms such as Hugging Face.
-
What Are Cloud Native Buildpacks?
Cloud Native Buildpacks (CNBs) are a specification & open-source tooling designed to transform application source code into OCI container images. They provide a higher-level abstraction compared to Dockerfiles, automating the process of detecting dependencies, installing necessary build tools & libraries and configuring the application runtime environment.
Key concepts in the buildpacks ecosystem include the following:
- Buildpack: It is a modular component that contributes to the image-building process. Buildpacks typically manage specific language runtimes (e.g., Java, Python, Go), frameworks or system dependencies.
- Buildpack API: It is a contract that defines the interaction between the lifecycle, Buildpacks and the builder image.
- Lifecycle: It is an executable that orchestrates the build process, including the detection, build and export phases.
- Builder: It is an OCI image containing the lifecycle and a curated set of Buildpacks and build-time dependencies.
- Stack: It consists of a build image (used for compilation and dependency installation) and a run image (the base image for the final container).
CNBs promote reproducible builds by encapsulating build logic within Buildpacks and ensuring a consistent build environment. This eliminates the “works on my machine” problem often associated with manual Dockerfile creation.
-
Cloud Native Buildpacks vs. Docker
While both CNBs and Docker are used to create container images, they differ significantly in their approach:
| Feature | Cloud Native Buildpacks | Docker |
| Abstraction Level | Higher; focuses on application code and dependencies | Lower; requires explicit instructions in a Dockerfile |
| Automation | Automates dependency detection and runtime configuration | Requires manual specification of all build steps |
| Reproducibility | Designed for reproducible and consistent builds | Relies on the correctness and consistency of the Dockerfile |
| Modularity | Uses modular buildpacks for different technologies | Monolithic Dockerfiles can become complex |
| Developer Experience | Often simpler for application developers | Requires more in-depth knowledge of containerization |
Docker provides fine-grained control over the image creation process, which is essential for complex or highly-customized scenarios. However, for many application deployments, Cloud Native Buildpacks offer a more streamlined and maintainable approach by abstracting away the underlying containerization details.
-
Tutorial for Using Cloud Native Buildpacks
Malax/buildpack-ollama simplifies running Ollama within a containerized environment. It manages the installation and configuration of Ollama, allowing you to focus on using the LLMs.
Prerequisites:
- Pack CLI: Install the pack command-line tool, which is used to build OCI images with Buildpacks. Installation instructions can be found on the official Buildpacks website.
- Docker: Ensure that Docker is installed and running on your system. Although we are not going to be using Docker to build images, we will use it as a container runtime to demonstrate running the containers.
Steps:
1. Create a Simple Application Directory: Although Ollama itself doesn’t require application code in the traditional sense when run standalone, Buildpacks expect a source directory. So, we’ll create an empty directory for this purpose.
mkdir ollama-app
cd ollama-app
2. Create a project.toml File: This file informs pack about the build process. For this simple case, we’ll specify the Ollama Buildpack.
[build]
buildpacks = [“ghcr.io/malax/buildpack-ollama”]
3. Save this file as project.toml in the ollama-app directory.
Build the Ollama Image: Use the pack build command to create the container image. Replace <your-dockerhub-username>/ollama with your desired Docker Hub repository or a local image name.
pack build <your-dockerhub-username>/ollama –builder paketobuildpacks/builder:base –project ollama-app
Here, we are using the paketobuildpacks/builder:base builder, which provides a standard build environment. Malax/buildpack-ollama will be detected and executed during the build process, downloading and configuring Ollama within the image
4. Run the Ollama Container: Once the image is built, you can run it using Docker. We’ll map the default Ollama port (11434) to your local machine.
docker run -d –name ollama -p 11434:11434 <your-dockerhub-username>/ollama
The -d flag runs the container in detached mode (in the background), and -p maps the ports.
Interact with Ollama: You can now interact with the Ollama API. For example, to list the available models:
curl http://localhost:11434/api/list
5. To Pull a Model (e.g., llama2):
curl -X POST http://localhost:11434/api/pull -d ‘{“name”: “llama2”}’
And to Generate Text:
curl -X POST http://localhost:11434/api/generate -d ‘{“prompt”: “Tell me a joke”, “model”: “llama2”}’
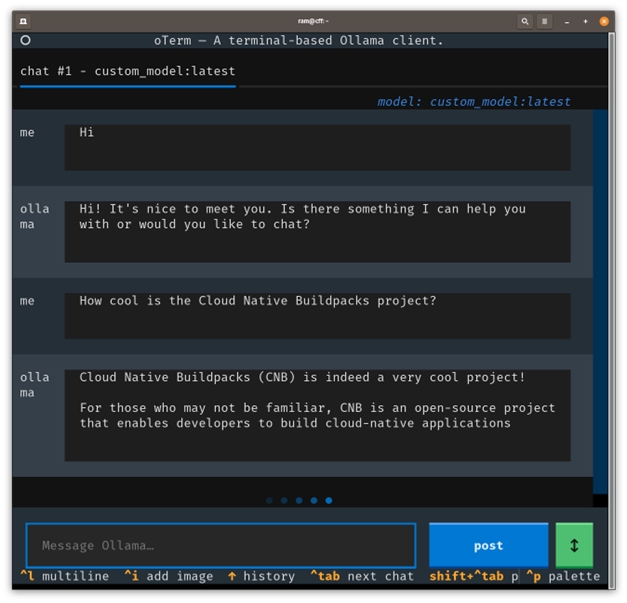
6. Alternatively, you could use a tool such as oTerm. This helps connect to a local LLM and works as a client.
Conclusion
Cloud Native Buildpacks provide an elegant and automated way to containerize applications and services. By leveraging Malax/buildpack-ollama, you can quickly and efficiently run Ollama locally within a container without the need for a complex Dockerfile. This approach promotes reproducibility and simplifies the management of your local LLM environment, allowing you to focus on exploring the capabilities of these powerful models.