
Qdrant has added an ability to better isolate workloads accessing its open source vector search engine to improve performance of artificial intelligence (AI) applications.
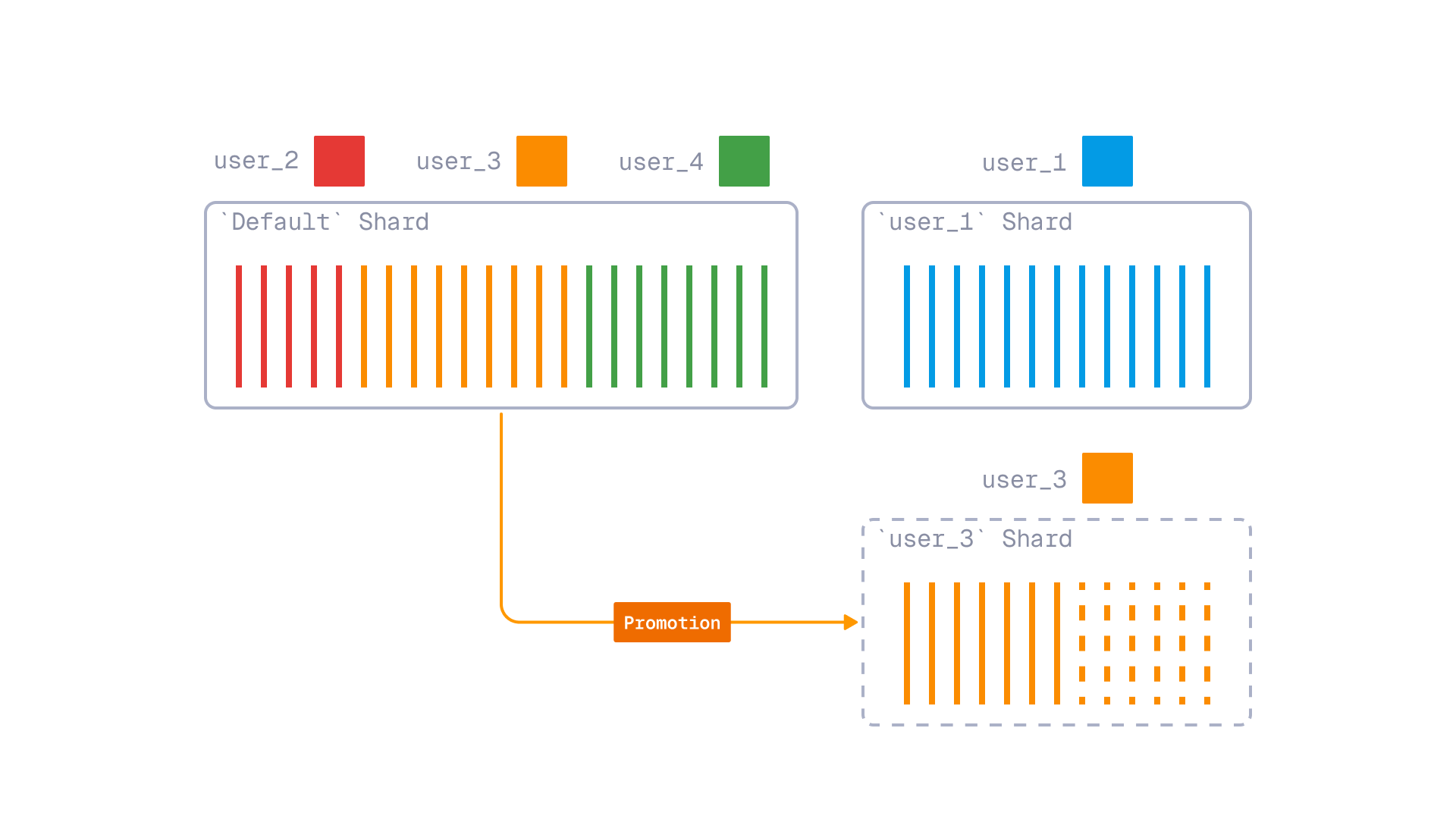
The Tiered Multitenancy capability added to the platform makes it possible to create a shard of the underlying vector database developed by Qdrant that can be dedicated to a specific workload, says Brian O’Grady, a solutions architect for Qdrant.
The overall goal is to minimize the impact of a “noisy neighbor” workload that might otherwise adversely impact the performance of another application, he adds. Via an application programming interface (API) that Qdrant exposes, an IT team can isolate a compute-intensive workload with a single call, notes O’Grady. “It creates a logical partition,” he says.
That approach, in effect, eliminates the need for complex client-side routing logic that would otherwise be needed to create a multi-tenant system.
Written in the Rust programming language to ensure applications run securely in memory, the overall goal is to provide organizations with a vector database that provides advanced search capabilities to AI applications using disk and memory resources as efficiently as possible, said O’Grady.
There is, of course, no shortage of vector database options. Some organizations are opting to deploy a dedicated vector database that typically scales higher while others are relying on vector extensions to existing databases to minimize total costs. Qdrant has already been installed more than 250 million times, with organizations such as Tripadvisor, HubSpot, and Deutsche Telekom having adopted it.
Less clear is to what degree database administrators (DBAs) are managing a dedicated vector database that might have been deployed to drive an AI application versus machine learning operations (MLOps) or DevOps teams. Over time, however, as more AI applications are built and deployed the need for some type of IT professional to manage these databases will become more acute. A recent Futurum Group survey, for example, found that data platforms (41%) are now the second highest AI investment priority for IT teams, second only to generative and agentic AI tools and platforms (52%).
The challenge right now is the number of IT professionals that have that expertise is somewhat limited. That might soon prove to be especially problematic when that lack of expertise starts to hamper the rate at which AI applications are being built and deployed.
In the meantime, however, interest in safely operationalizing AI using data that a large language model (LLM) was not initially trained on remains a top priority for enterprise IT teams. Achieving that goal requires putting in place guardrails that ensure the data being exposed to those LLMs has enough context to generate a reliable output. Otherwise, the probability that the LLM will generate “AI slop” will only continue to increase. In fact, it’s arguable that many organizations are not seeing the return on their AI investment that was expected simply because they lack the data management and engineering expertise required.
It is, of course, at this point more a question of when, rather than if, organizations will recognize this issue. However, exactly how to go about fixing it may require additional levels of investment that many of the organizations did not initially set aside enough budget to really address.