

Red Hat today moved to reduce the complexity of building and deploying artificial intelligence (AI) applications by updating a platform that combines an inference server with an application development and deployment framework based on Kubernetes and a distribution of Linux optimized for these types of applications.
The Red Hat AI 3 platform is based on Red Hat AI Inference Server, Red Hat Enterprise Linux AI (RHEL AI) and Red Hat OpenShift AI in a way that promises to make it simpler for IT teams to mix and match AI accelerators and large language models (LLMs) as they best see fit.
At the core of that effort is llm-d, an open source originally developed at the Sky Computing Lab hosted by the University of California at Berkeley. Red Hat, with the release of the third version of the Red Hat AI platform, is now generally making available a set of llm-d containers that can be deployed on a Red Hat OpenShift AI platform based on Kubernetes. Dubbed the vLLM Inference Server, that offering is based on a platform that Red Hat gained with its acquisition of Neural Magic, which makes it possible to distribute AI workloads running large language models (LLMs) across multiple Kubernetes clusters. That approach, in effect, provides IT organizations with an alternative to CUDA, the framework developed by NVIDIA for deploying AI applications on its processors.
The platform is designed to make it simpler to acquire the AI tools and the underlying instances of Kubernetes and operating systems needed to create an integrated platform that is simpler for IT teams to manage, says Joe Fernandes, vice president and general manager for the AI business unit at Red Hat. “Our focus is on providing an enterprise-grade platform to build, deploy and manage AI models training and agentic applications across a hybrid cloud environment,” he adds.
The overall goal is to create a model-as-a-service (MaaS) environment using an AI gateway that has been integrated into a Kubernetes cluster to make it simpler to scale compute resources up and down as needed, says Fernandes.
Red Hat AI 3 also provides access to an AI hub that provides access to a curated catalog of foundational AI models and extensions, including open source models such as gpt-oss from OpenAI, DeepSeek-R1, and specialized models such as Whisper for speech-to-text and Voxtral Mini for voice-enabled agents. It also includes a registry to manage the lifecycle of models, a deployment environment to configure and monitor all AI assets running on OpenShift AI and support for the Model Context Protocol (MCP) server developed by Anthropic. Red Hat is also making available a compression tool to run AI models more efficiently.
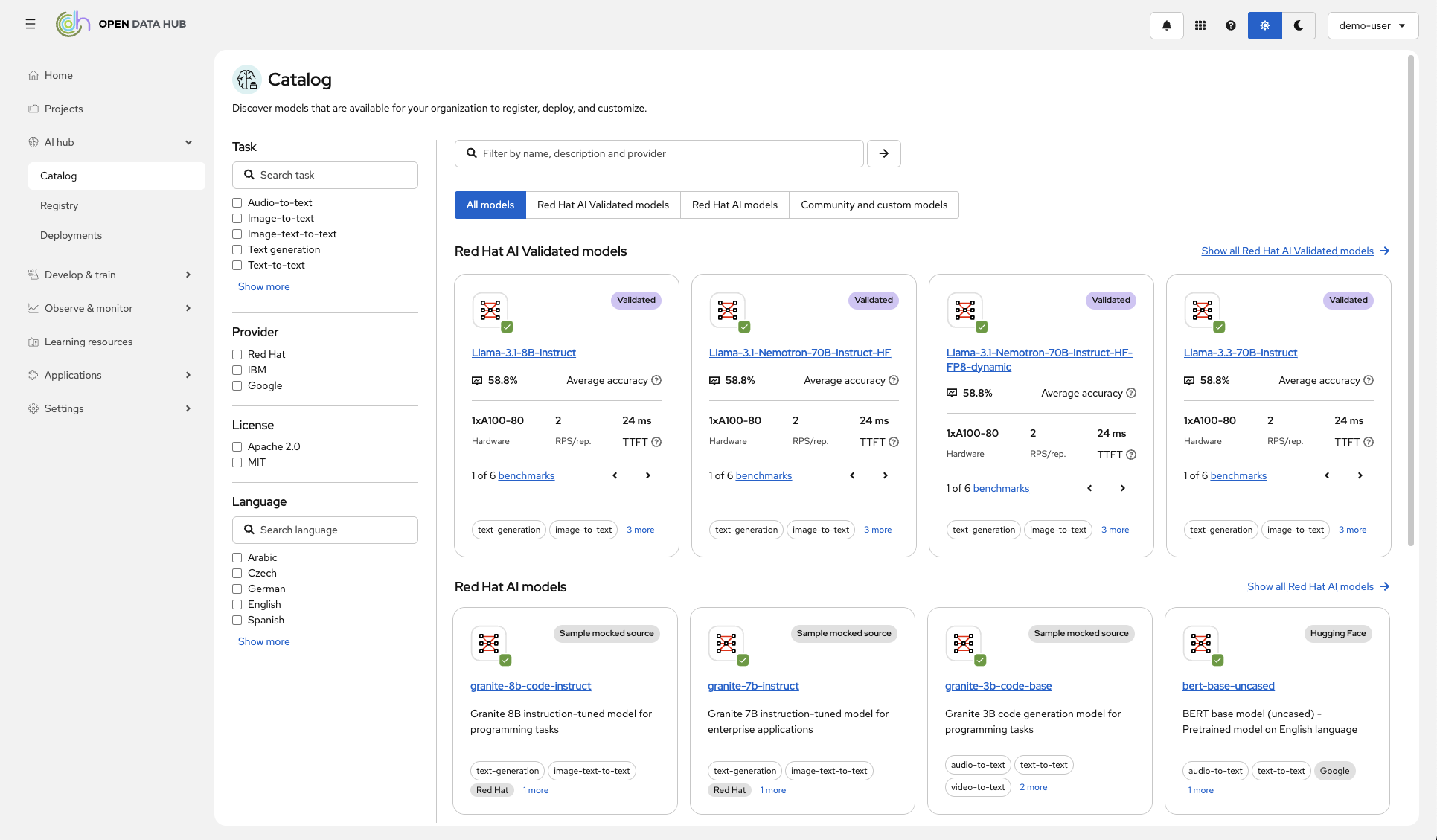
Red Hat is also providing access to Gen AI studio, a tool for prototyping generative AI applications and Llama Stack, a framework for building application programming interfaces (APIs) that are compatible with a de facto standard defined by OpenAI.
Finally, Red Hat AI 3 includes a modular and extensible InstructLab tool customizing AI models using private data that is based on a set of Python libraries and an open source Docling platform for processing data in a way that streamlines the ingestion of unstructured documents into an AI-readable format.
It’s not clear at what pace IT teams are starting to deploy AI models across distributed computing environments, but as more of these compute-intensive applications are deployed, the need to find ways to more efficiently consume infrastructure resources is going to become a much more pressing issue.