
It has long been a difficult task to generate precise SQL queries from customers’ natural language inquiries (text-to-SQL).
Understanding user queries, appreciating the structure and semantics of a particular database schema and accurately producing executable SQL statements are some of the elements that contribute to the complexity.
Large language models (LLMs) have opened up new avenues for text-to-SQL research. Superior natural language understanding skills demonstrated by LLMs and their scalability offer special chances to improve SQL creation.
Methodology
The implementation of LLM-based text-to-SQL methods primarily depends on two key paradigms:
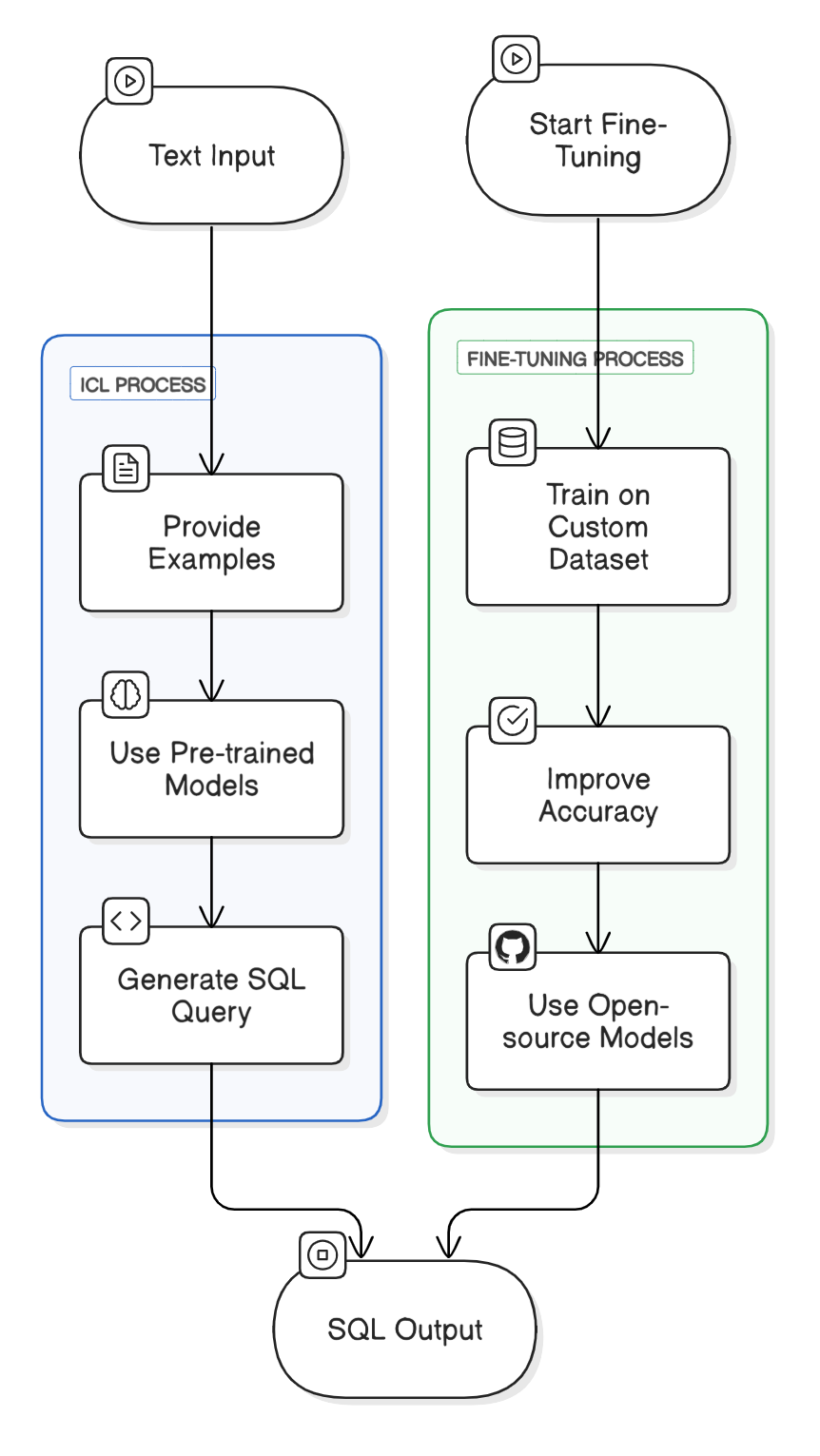
1. In-Context Learning (ICL):
-
- Instead of retraining the model, ICL allows LLMs to generate SQL queries by providing relevant examples or schema details in the prompt.
- Example: Giving the model table structures and a few question-SQL pairs as context before asking it to generate a query.
- This method leverages powerful pre-trained models like GPT-4 or LLaMA without additional fine-tuning.
2. Fine-Tuning:
-
- This involves training an LLM on a custom dataset of natural language queries and their corresponding SQL translations.
- Fine-tuning improves accuracy, especially for domain-specific databases or complex SQL queries.
- Open-source models like LLaMA, T5 and BART can be fine-tuned for better performance.
Technical Challenges in Text-to-SQL
Text-to-SQL models face several challenges:
- Understanding User Queries – Questions can be unclear or incomplete, requiring smart language processing.
- Mapping to the Database – The model must correctly match user questions to different database structures.
- Generating Accurate SQL – Creating correct and meaningful SQL queries is difficult, especially for complex cases.
- Adapting to New Databases – Many models struggle with new database formats without extra training.
- Efficiency and Scalability – Queries must be generated quickly and accurately, even for large databases.
Evolution of Text-to-SQL Systems
Text-to-SQL methods have evolved over time:
- Rule-Based and Template Methods – Early systems used fixed templates and rules to convert text into SQL, but they were inflexible and required a lot of manual work.
- Neural Network Approaches – Deep learning models improved SQL generation by learning from data instead of relying on fixed rules.
- Pre-Trained Language Models (PLMs) – Models like BERT and T5 were fine-tuned for text-to-SQL, improving accuracy using contextual understanding.
- Large Language Models – Advanced models like GPT-4 and PaLM handle complex queries better, thanks to their extensive training on diverse datasets.
Advances in LLM-Based Text-to-SQL
LLMs have greatly improved text-to-SQL generation by:
- Better Understanding – They grasp user intent more accurately, reducing confusion.
- Learning Without Extensive Training – LLMs can generate SQL with little to no fine-tuning using in-context learning.
- Adapting to Different Databases – They adjust to various database structures using smart prompts.
- Handling Complex Queries – They create more accurate SQL queries, even for difficult tasks.
- Supporting Conversations – LLMs can remember context across multiple interactions, improving responses in multi-turn dialogues.
Challenges and Future Research Directions
LLM-based text-to-SQL systems still have some challenges:
- Incorrect SQL (Hallucinations) – Sometimes, they generate SQL that looks right but doesn’t actually work.
- High Costs – Running large models requires a lot of computing power, making real-world use expensive.
- Data Privacy Concerns – Keeping user data secure and meeting regulations is a major challenge.
- Hard to Debug – Fixing mistakes in AI-generated SQL can be tricky.
- Real-World Integration – Adapting to different databases, especially in large companies, needs improvement.
An important development in natural language database querying is the incorporation of LLMs into text-to-SQL systems. As the integration becomes tighter and they develop further, LLMs will be essential in bridging the gap between formal database interactions and natural language understanding.