
Tecton today launched a platform that makes it simpler to extend large language models (LLMs) using retrieval-augmented generation data to continuously expose data in real time.
Available as a public preview, the capabilities enabled by the Tecton platform will substantially improve the output of LLMs by exposing them to domain-specific data in real time, says Tecton CEO Mike Del Balso.
That additional context is critical for organizations attempting to embed LLMs within business processes, such as e-commerce transactions, that require access to the latest available data, he adds.
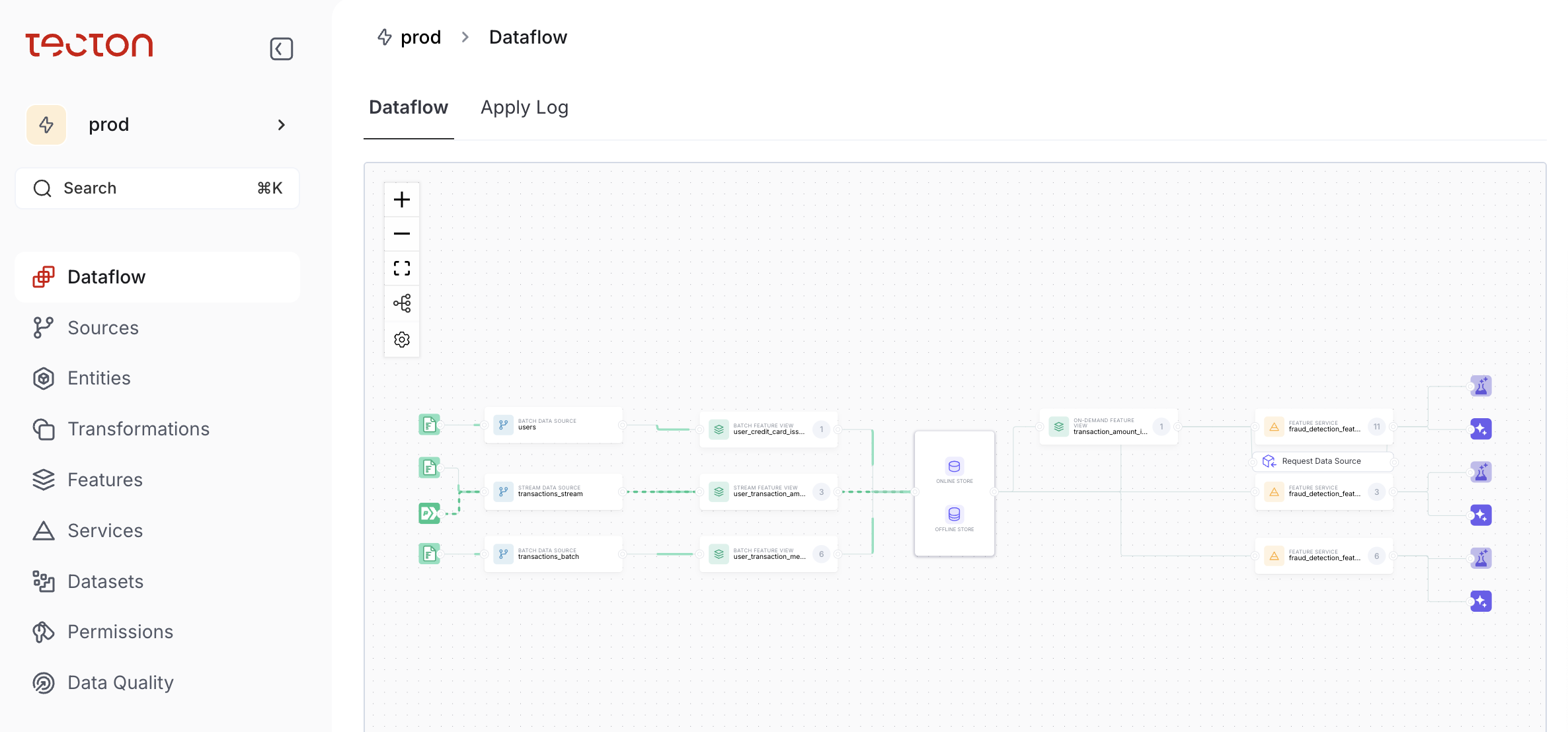
The Tecton platform provides a suite of capabilities to manage embeddings, integrations with various LLM and prompts to more efficiently transform text into numerical vectors that capture semantic meaning using a Feature Retrieval application programming interface (API). For example, Tectron in real time can convert a customer review into a numerical vector that encodes the sentiment, topic and other key aspects. These vector representations can then be stored in a vector database along with thousands of other reviews.
The overall goal is to provide a declarative framework that reduces the overhead of managing the embeddings lifecycle using an API that employs caching and rate limiting to reduce costs while ensuring sensitive data is only shared with authorized LLMs, says Del Balso.
A Dynamic Prompt Management capability also enables version control of prompts to track changes and, when necessary, roll prompts back.
It’s still early days in terms of how organizations are operationalizing generative AI, but LLMs are only as valuable as the quality of the data being exposed. Organizations of all sizes are investing in data engineering skills to automate the processes through which LLMs can be customized using data generated after the LLM has been initially trained. The challenge they face is finding a way to make data as it is created available to LLMs that are driving real time business processes, says Del Balso. “The better the data the better the model performs,” he adds.
That data can then be stored in a feature store within the context of a larger machine learning operations (MLOps) workflows that will be used to train AI agents to repeatedly automate specific tasks using the reasoning capabilities built into an LLM, notes Del Balso.
It’s not yet clear just how LLMs and MLOps will be managed at scale. Many organizations have created so-called Tiger teams to initially operationalize LLMs, but in time data scientists will focus their efforts on training LLMs while data engineers working alongside IT operations teams manage the underlying IT infrastructure. The challenge right now is bringing these respective teams together in a way that enables organizations to employ multiple LLMs that will, over time, need to be regularly retrained and replaced.
Of course, organizations today have more data management challenges than they care to admit, so it may be a while before the processes are in place that ensures the right data is being exposed to an LLM at the right time.