

As manufacturing enters the next phase of digital transformation, voice technology is emerging not as an optional layer but as a foundational interface. In factories, where hands are occupied, protective gear is standard and background noise is constant, voice-based systems offer a compelling, frictionless way to bridge human and machine interaction. Artificial intelligence (AI)-driven speech interfaces are proving to be more than just convenience tools; they are enabling real-time decision-making, ensuring safety compliance and enhancing operational efficiency across industrial settings.
Why Voice System is Ideal for Industrial Environments
Unlike in consumer applications, where voice assistants are primarily about ease of use, in manufacturing, voice interfaces solve tangible, on-the-ground challenges. Workers on assembly lines, maintenance personnel and machine operators are often mobile, wearing gloves and handling equipment in physically demanding environments. Under such conditions, traditional interfaces such as touchscreens or keyboards are inefficient or unusable. Voice becomes the most natural interface, allowing users to issue commands, retrieve data or initiate workflows through simple spoken interaction.
However, manufacturing settings pose a unique set of acoustic challenges. High levels of ambient noise, reverberation and the presence of multiple speakers can degrade speech recognition accuracy unless the system is specifically engineered for such use cases.
AI at the Edge: Enabling Real-Time, Low-Latency Voice Interfaces
Low latency is not merely a user experience concern in industrial settings; it can be a matter of safety. Factory operations demand immediate responsiveness, especially for commands like halting a malfunctioning conveyor or triggering emergency protocols. In these contexts, voice recognition must work with minimal delay and maximum reliability.
This is where edge AI becomes crucial. Modern industrial voice systems are increasingly running inference locally using lightweight, quantized neural networks. These models are optimized to run on edge devices such as embedded controllers, smart headsets or DSP-enabled microphones. Wake-word detection is typically handled on-device to avoid unnecessary processing, while domain-trained acoustic models help filter out industrial noise patterns like compressor hissing or mechanical clatter. The result is a speech interface that responds in under 100 milliseconds, with no dependence on the cloud and no compromise on reliability.
To illustrate how modern voice-enabled systems operate on the factory floor, Figure 1 shows a typical architecture for edge-based voice processing. The flow begins with a microphone array that performs beamforming and noise suppression, followed by wake-word detection and real-time automatic speech recognition (ASR) on embedded hardware. The extracted intent can then be executed locally or, in more complex cases, relayed to cloud-based natural language processing (NLP) systems. This hybrid setup ensures ultra-low latency, privacy and resilience in environments where connectivity is not guaranteed.

Figure 1: Edge voice system architecture for industrial environments, illustrating the path from acoustic input to actionable intent across edge and cloud components.
While Figure 1 outlines the architectural flow of edge-based voice systems, Table 1 provides a detailed comparison between edge and cloud-based speech processing in manufacturing environments. It highlights the trade-offs in latency, privacy, connectivity and robustness, underscoring why edge inference is increasingly being preferred for time-sensitive and privacy-critical applications on the factory floor.
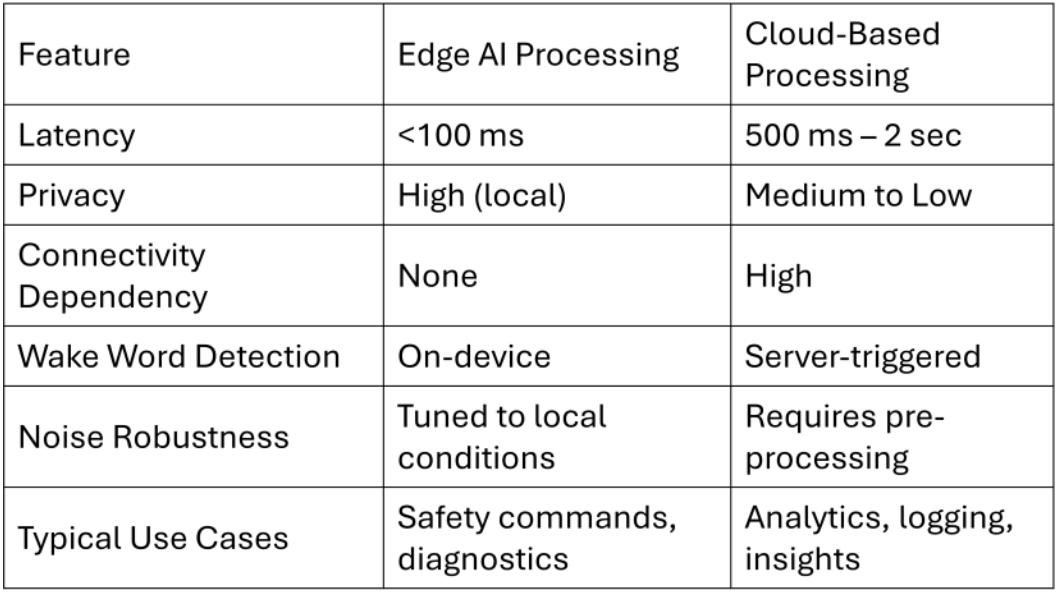
Table 1: Comparison of Edge AI and cloud-based voice processing systems in industrial environments, showing differences in latency, privacy, and deployment constraints.
Real-World Applications Already in Deployment
Many manufacturing environments are already benefiting from voice-integrated workflows. In some facilities, operators can verbally request diagnostic summaries or sensor reports while continuing to monitor equipment hands-free. Maintenance technicians use voice commands to log repairs, dictate fault descriptions and query service history – automatically parsed and logged by NLP-driven backends. Warehouses are adopting voice-activated inventory systems that enable instant reporting of material requests and stock discrepancies. Multilingual teams are leveraging voice translation systems to improve collaboration and safety. In time-critical scenarios, shouting a pre-trained phrase such as ‘emergency stop’ can trigger factory-wide alerts faster than manual intervention.
These are not futuristic concepts – they are active deployments enabled by real-time voice technology and AI-powered speech processing.
Solving the Noise Problem: Beamforming and Adaptive Filtering
One of the biggest hurdles in deploying voice systems in manufacturing is ensuring clarity and robustness in extremely noisy conditions. Many environments have continuous ambient sounds from machinery, heating, ventilation and air conditioning (HVAC) systems or alarms that can interfere with voice input. To mitigate this, industrial-grade audio wearables and headsets are now designed with multi-microphone arrays that enable directional beamforming, allowing the system to isolate the speaker’s voice from surrounding noise. Acoustic echo cancellation (AEC)further cleans the signal by removing reflections caused by enclosed spaces or metal surfaces. In some cases, advanced neural separation techniques are applied to extract clean speech even in overlapping speaker scenarios. These include models trained with convolutional architectures or transformer-based pipelines capable of real–time source separation. Combined with adaptive noise suppression, these techniques enable reliable voice recognition even under the harshest acoustic conditions.
Given the acoustic complexity of manufacturing environments, voice systems rely on a carefully engineered processing chain to clean the audio signal before interpretation. As shown in Figure 2, the pipeline begins with raw audio input and applies beamforming to focus on the primary speaker. This is followed by (AEC), deep learning-based noise suppression and keyword or intent detection. Each stage is optimized for real-time processing on edge devices with constrained compute resources.

Figure 2: End-to-end speech enhancement and recognition pipeline designed for industrial noise, including beamforming, AEC, DNN noise suppression and edge ASR.
Training ASR Models for Industrial Domain
Out-of-the-box speech recognition models typically fail in industrial contexts due to their lack of exposure to specialized vocabulary, high background noise and diverse speaker accents. To achieve meaningful performance, ASR systems must be fine-tuned on domain-specific datasets that reflect real-world operating environments. This involves retraining existing acoustic models with labeled recordings from factory floors and introducing noise augmentation techniques during model training. To address workforce diversity, phoneme adaptation and accent normalization techniques are also applied to enhance robustness to non-native speech patterns.
In some deployments, keyword spotting is implemented using efficient mel-frequency cepstral coefficients (MFCC)- or log-mel-based models that operate well in constrained environments. More advanced architectures use a hybrid approach – lightweight parsing is handled at the edge for fast response, while complex language understanding is deferred to cloud systems that asynchronously process and contextualize interactions.
Selecting the right ASR engine is crucial for achieving reliable performance in the noisy and variable conditions typical of factory settings. Table 2 benchmarks several ASR models across key dimensions, including parameter size, noise robustness, inference latency and adaptability to domain-specific vocabulary. These technical characteristics directly impact the feasibility of deploying ASR on embedded or constrained hardware.
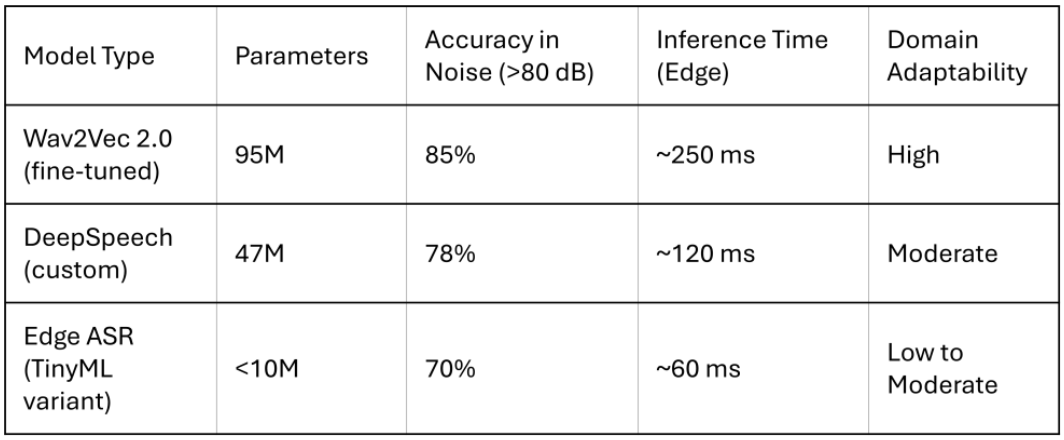
Table 2: Benchmark comparison of common ASR models adapted for noisy manufacturing environments, showing trade-offs in accuracy, inference time and model complexity.
What’s Next: Voice Agents as Industrial Co-Workers
As these technologies mature, voice systems will evolve beyond reactive interfaces. Soon, AI voice agents will actively guide workers through procedures, flag anomalies in real–time and offer proactive suggestions based on contextual data. By integrating voice with sensor data, computer vision and historical analytics, these agents will become intelligent collaborators rather than passive tools.
For example, a worker assembling a complex machine may receive step-by-step voice guidance, while the system monitors torque readings and visually confirms the placement of each part. If a deviation is detected, the agent can issue a warning and suggest corrective actions – all communicated in natural language through voice. This convergence of voice, AI and context-awareness will redefine human-machine collaboration on the factory floor.
Closing Thoughts
Over the past decade, voice has become a viable interface for cars, homes and personal devices. Now, it is rapidly proving its value in high-stakes industrial environments. When engineered with the right blend of real-time signal processing, robust acoustic modeling and domain-specific training, voice systems offer more than just convenience – they enhance safety, streamline workflows and unlock a new paradigm of interaction between humans and machines. In manufacturing, voice is no longer an afterthought – it is becoming the ambient operating system that powers the factory of the future.