

Deepgram today revealed it has inked a strategic collaboration agreement (SCA) with Amazon Web Services (AWS) through which it expects to further accelerate the development of voice-enabled artificial intelligence (AI) applications.
The multi-year generative voice AI technologies alliance promises to make it simpler to gain access to speech-to-text (STT), text-to-speech (TTS), and speech-to-speech (STS) capabilities, which will become accessible to a wider range of application developers, says Abe Pursell, vice president of business development and partnerships for Deepgram. “It’s a much deeper partnership with AWS,” he says
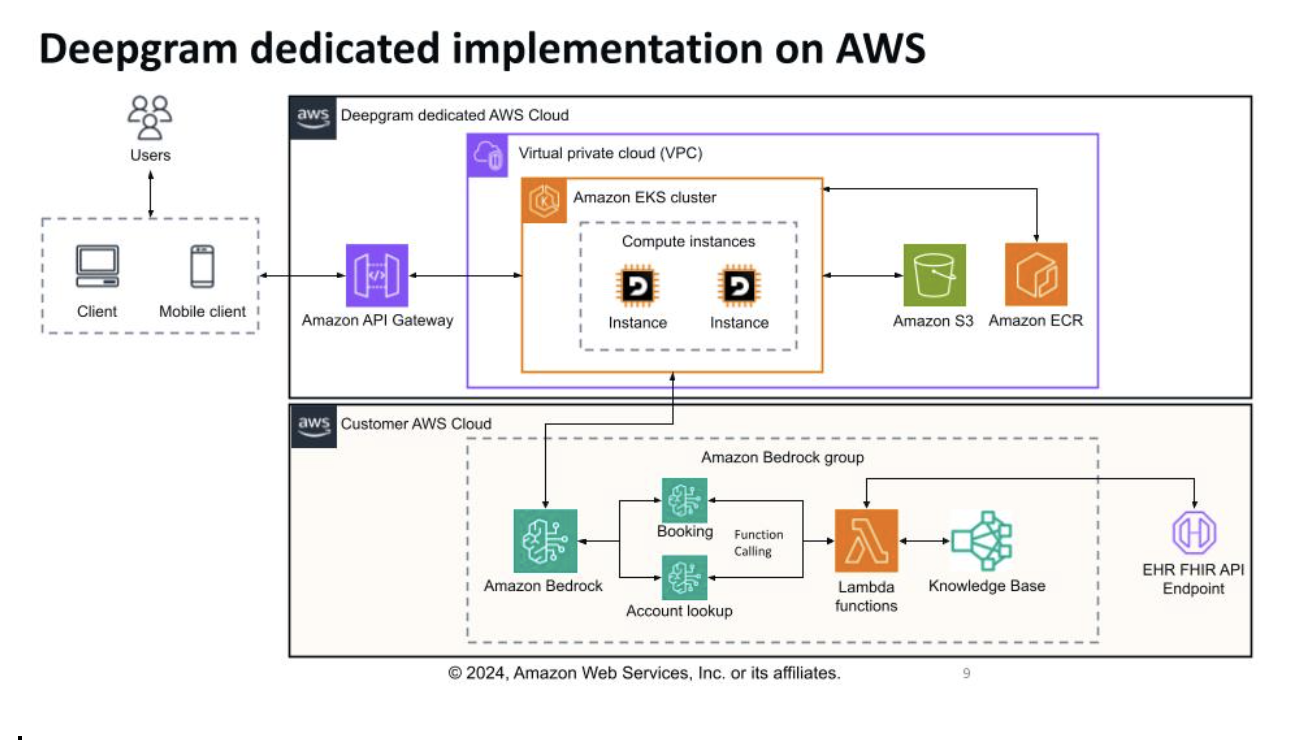
The Deepgram platform is already deeply integrated with AWS, enabling IT teams to deploy it on the Amazon Elastic Kubernetes Service (EKS) service while storing data on the Amazon S3 cloud storage service. IT teams can also invoke application programming interfaces (APIs) via the Amazon API Gateway and AWS Lambda serverless computing framework to securely orchestrate interactions between Deepgram’s voice AI APIs and other services, including the Amazon Bedrock service for hosting AI models.
The Deepgram speech-to-text API can also be integrated into Amazon Connect to enable real-time transcription and voice automation within contact center environments.
Finally, Deepgram also plans to expand accessibility via other AWS services such as the Amazon SageMaker service for creating AI models.
Deepgram earlier this year rolled out Nova 3, a more advanced artificial intelligence (AI) model that enables speech-to-text (STT) communications in near real time. Based on a latent space architecture that compresses representation of data points in a way that preserves only the essential features needed to inform the input data’s underlying structure, it is designed to encode complex speech patterns into a highly efficient representation while providing higher levels of accuracy.
That approach enables the Nova 3 model to, for example, accurately transcribe speech in environments such as restaurants where there tends to be a lot of background noise that needs to be filtered. The Nova 3 model enables real-time transcription across multiple languages, including applications that require domain-specific terminology, such as emergency response services. Deegram also claims Nova-3 is the first voice AI model to enable self-serve customization by allowing users to fine-tune the model for specialized domains without requiring deep expertise in machine learning. Keyterm Prompting, for example, makes it possible to improve transcription accuracy by optimizing up to 100 key phrases without having to retrain the underlying model.
At the same time, organizations can apply policies and controls to redact sensitive information in real time to ensure compliance and data privacy mandates are met.
All told, Deepgram claims to have now processed more than 50,000 years of audio involving greater than one trillion words.
Regardless of approach, it’s already clear that voice-enabled AI applications will increasingly become the default user experience that no text-based set of prompts entered into a chat interface will ever match in terms of natural interactivity. The challenge now is finding a way to provide those types of user experiences in ways that are not only simpler to create but also less expensive to employ.