
In today’s data-driven business environment, companies rely on emails for handling customer service requests, sales inquiries, support tickets, and other critical operations. However, the unstructured email content which varies widely in style, tone, and complexity, creates obstacles for systematic organization and analysis.
The primary challenge lies in manually processing the emails. Insurance service agents are required to review thousands of daily emails and extract critical information such as claims details, policy numbers and customer inquiries from them. A highly labor-intensive process, it requires agents to read, interpret, and enter information into their database all by hand. The approach, besides being time-consuming, is fraught with human error that accounts for data inconsistencies and delayed response times.
The unstructured nature of emails presents further complexities in data extraction. Valuable information is often buried within lengthy email threads, intermingled with non-essential elements like greetings, disclaimers, and email signatures. This format makes it particularly challenging to glean insights.
Converting this unstructured content into a structured format enables organizations to effectively categorize, label, and organize their data. It makes information readily accessible for integration with other business systems, such as customer relationship management (CRM) platforms and analytics tools. Once structured, the information can be analyzed for patterns in customer feedback, track common complaints, and identify emerging trends.
This systematic approach to data management enables companies to understand customer preferences and proactively address issues before they escalate, ultimately leading to improved customer satisfaction and more efficient operations.
An innovative solution that uses UiPath’s automation tool capabilities combined with ML model – Named Entity Recognition (NER) can help streamline these data labeling processes and enhance accuracy of information extraction, thus transforming email content at runtime and facilitating the shift from unstructured to structured data.
System Architecture
1. Email Processing with UiPath: UiPath bots read incoming emails, extract email content, and route it to the next processing stage. UiPath’s workflow automation capabilities make it easy to extract attachments, analyze metadata, and categorize the emails based on predefined rules.
2. Text Preprocessing
Once emails are extracted, they pass through a preprocessing pipeline the content is prepared for entity recognition. This pipeline includes HTML cleanup, removal of elements like email signatures and disclaimers, and text standardization. These steps ensure that the content is clean and suitable for natural language processing (NLP).
Key components include:
– HTML cleanup and normalization of text to remove artifacts.
– Removal of irrelevant information like signatures and legal disclaimers.
– Segmentation into sentences for more structured analysis.
– Token normalization to standardize variations in words and phrases.
3. Structured Data Extraction with NER: By integrating NER models, companies can identify and label critical entities such as dates, customer names, policy numbers, and claim amounts within the unstructured email text. The NER model classifies and organizes these elements into structured data that can then be directly entered into the company’s systems.
4. Improved Efficiency and Decision-Making: With structured data extracted and organized, the company can run analytics on common claim issues, track response times, and even flag potential fraud cases more efficiently.
This combined approach not only cuts down processing time but also improves accuracy while shrinking operational costs. It is ideal for businesses dealing with large volumes of unstructured data that are looking to transform email content into valuable, actionable insights.
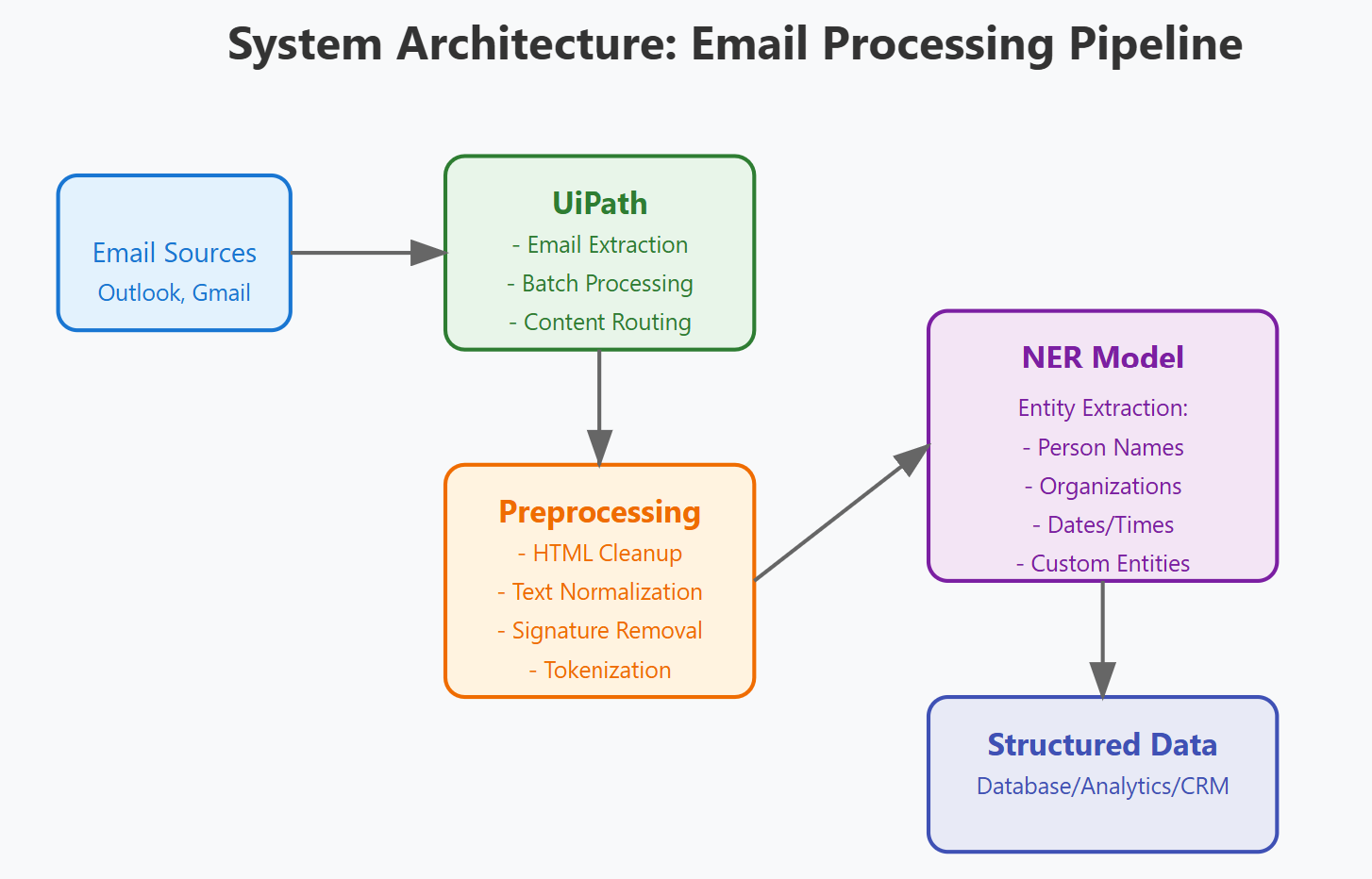
By integrating UiPath with a preprocessing pipeline and NER, this system architecture enables efficient transformation of unstructured email content into actionable, structured data.
Code for Step-by-Step Runtime Flow
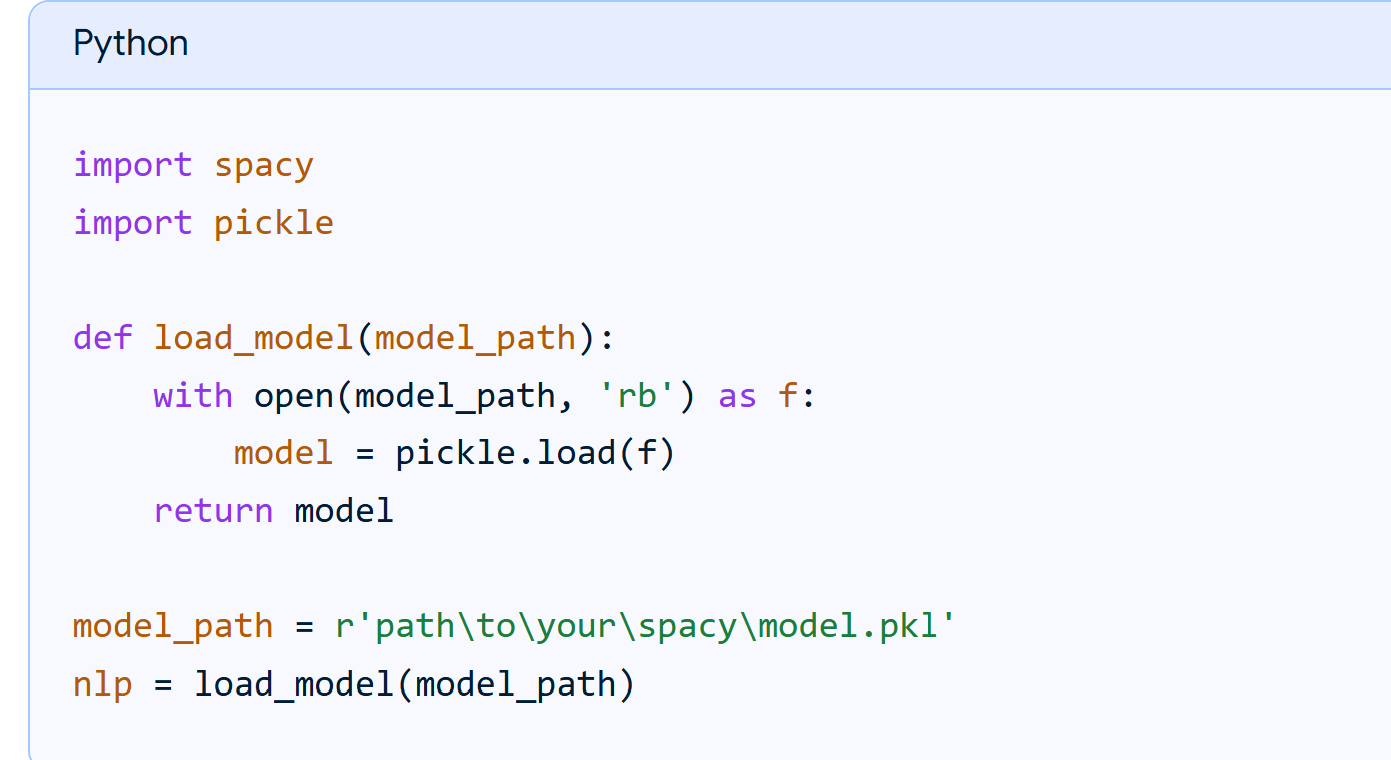
Step 1: Create ML spaCy model using trained dataset, and generate *.pkl file and load –
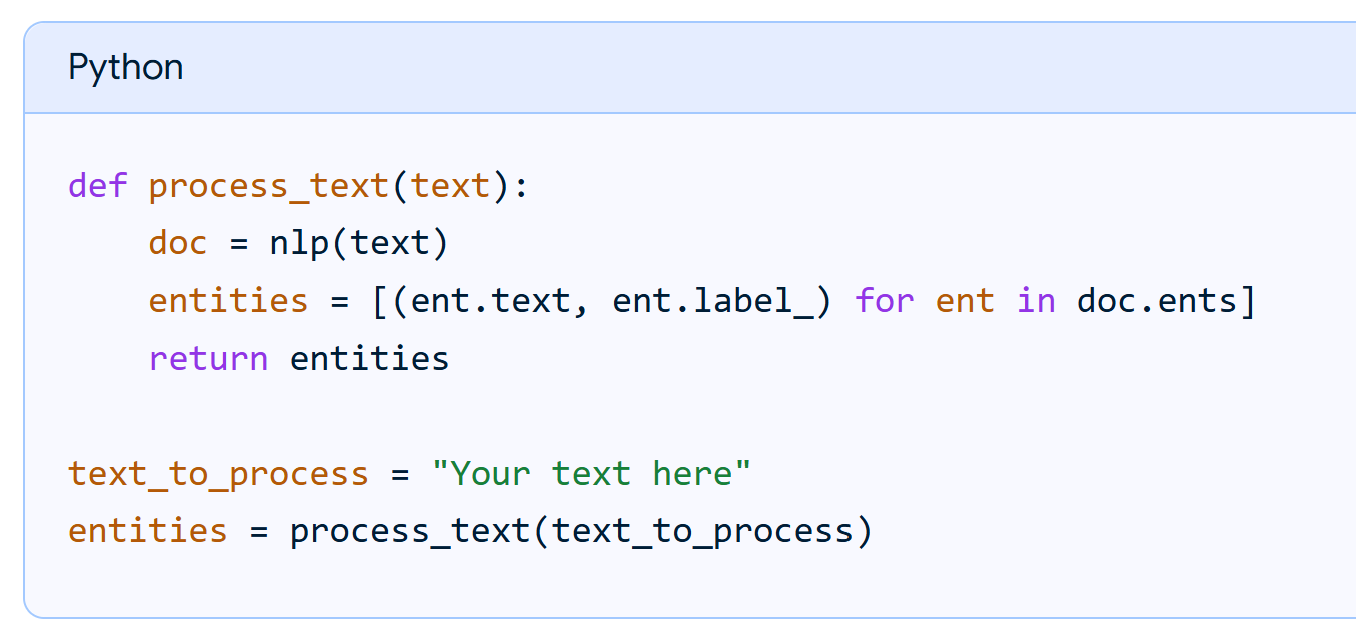
Step 2: Feed email’s preprocessed text in text_to_process variable; model will generate output –
- Pass email text from UiPath:
Use an Invoke Python Method activity in UiPath to pass the email text.
- Extract entities:
In the Python script, use the loaded spaCy model to process the text and extract the named entities.
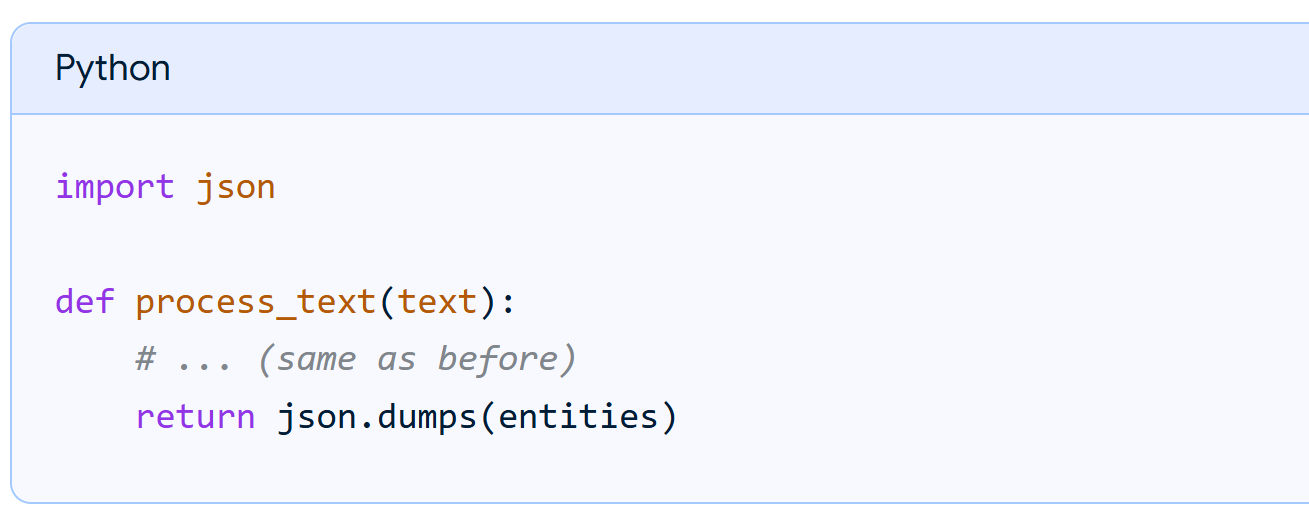
Step 3: Return output (entities) from NER model to UiPath
- Serialize entities:
Convert the extracted entities into a JSON string using the json.dumps() function in Python.
- Output JSON:
Return the JSON string to UiPath using the Out argument of the Invoke Python Method activity.
Step 4: Use entities in UiPath
- Deserialize JSON: Use the Deserialize JSON activity in UiPath to convert the JSON string back into a structured data type (e.g., a dictionary or a list).
- Process entities: Use the extracted entities in your UiPath workflow as needed.
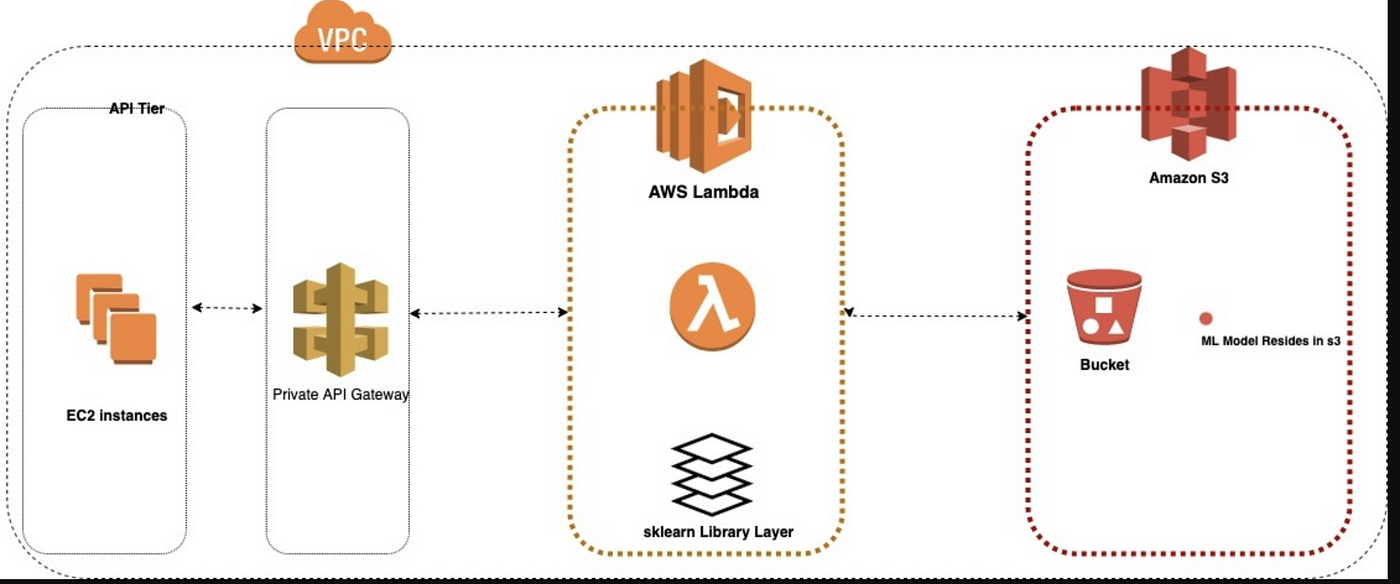
ML Model Deployment
To deploy this pre-trained machine learning (ML) model on AWS Lambda, place the pickle file in Amazon S3 bucket. The AWS Lambda function will download this file whenever needed, eliminating the need to store the model directly within the Lambda environment, which has size limitations.
Now integrate this lambda function with AWS API Gateway so that for each API Gateway invocation, the Lambda function retrieves the model from S3, deserializes it, and applies it to incoming data provided in the event payload. The output from the Lambda function will return the expected predictions.
In conclusion, integrating UiPath’s automation tool with Named Entity Recognition (NER) models provides a robust solution for efficiently generating structured, labeled datasets from unstructured email content. This approach significantly minimizes manual effort while improving accuracy in extraction and categorization of entities. Processing time per email comes down to under 30 seconds and data extraction accuracy goes up to 95%.
A solution like this can help organizations shift their focus from routine data entry tasks to more strategic ones, like resolving claims issues, while helping enhance customer satisfaction with faster response times.