
The U.S. National Institute of Standards and Technology (NIST), which is evolving to become the lead Federal agency tasked with overseeing AI, has some bad news. As detailed in a new NIST research paper, no foolproof method exists as of yet for protecting AI from misdirection, and AI developers and users should be wary of any who claim otherwise. Essentially, there are just too many waypoints where an AI can be compromised and there is no silver bullet available to prevent it. And it’s all way too easy.
“Despite the significant progress AI and machine learning have made, these technologies are vulnerable to attacks that can cause spectacular failures with dire consequences,” says NIST computer scientist Apostol Vassilev, one of the authors of Adversarial Machine Learning: A Taxonomy of Attacks and Mitigations. “There are theoretical problems with securing AI algorithms that simply haven’t been solved yet. If anyone says differently, they are selling snake oil.”
The NIST report highlights a basic conundrum underlying AI development. “For the most part, software developers need more people to use their product so it can get better with exposure,” says Vassilev. “But there is no guarantee the exposure will be good. A chatbot can spew out bad or toxic information when prompted with carefully designed language.”
A major issue is that AI data itself may not be trustworthy given that its sources may be websites and interactions with the public, notes the report. There are many opportunities for bad actors to corrupt this data. This can occur during an AI’s training period and afterward while the AI continues to refine its behavior by interacting with the physical world.
The NIST report is designed to provide an alert as to the various types of AI poison pills developers may encounter but remedies may be elusive. “We are providing an overview of attack techniques and methodologies that consider all types of AI systems,” explains Vassilev. “We also describe mitigation strategies reported in the literature but these available defenses currently lack robust assurances that they fully mitigate the risks. We are encouraging the community to come up with better defenses.”
NIST describes AI attacks in four broad categories:
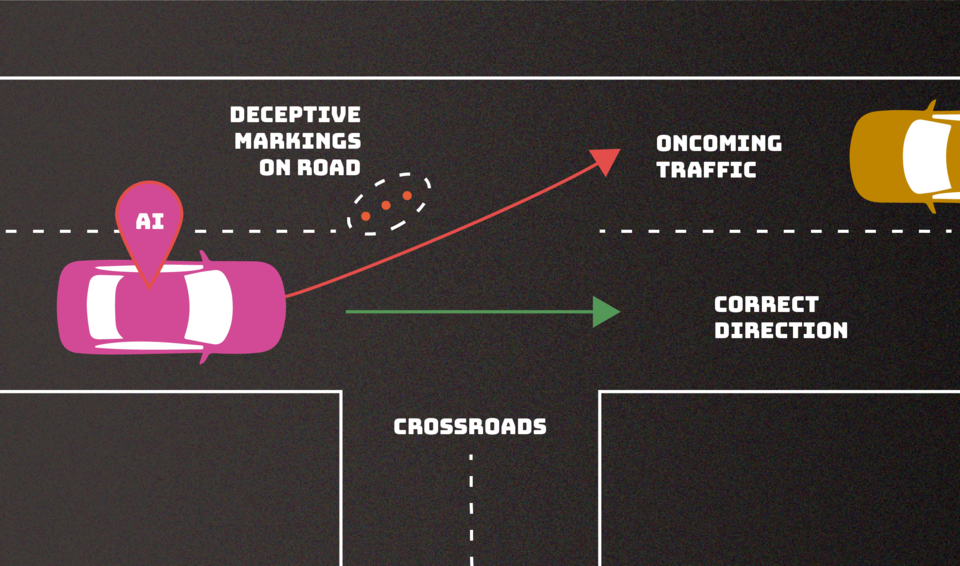
—Evasion attacks, which occurs after an AI is deployed, that attempt to alter an input to change how an AI responds to it. An example would be adding markings to road signs to make an autonomous vehicle misinterpret speed limits or creating confusing lane markings that cause the vehicle to veer off the road.
—Poisoning attacks that occur in the training phase by introducing corrupted data. An example would be adding inappropriate language into conversation records that a chatbot interprets as common parlance to use with customer interactions. Scraping of data from the internet increases the chances of data poisoning and the insertion of “Trojans” that can cause the AI to leak data at a later date when instructed.
—Privacy attacks, occurring during deployment, in which attempts are made to learn sensitive information about the AI or the data stored on the AI to misuse it. An adversary can ask legitimate questions but use those answers to reverse engineer the AI model to find weak spots that make the AI behave badly, behaviors that can be difficult for the AI to unlearn.
—Abuse attacks involve the insertion of incorrect information into an AI data source. This type of attack attempts to add false information from a legitimate but compromised source in order to repurpose that AI’s intended use.
Each of these categories contains subcategories within it which hint at the potential pervasiveness of the issue. Poisoning subcategories, for example, include Targeted Poisoning, Backdoor Poisoning and Model Poisoning. The report runs to 106 pages, delving into such distinctions like white, black and grey box attacks defined by the level of access an adversary might have to an AI. One adversary technique, for example, is to condition an AI to commence responses with an affirmative confirmation in an attempt to influence the AI’s language generation toward specific predetermined patterns or behaviors.
One area of high concern is the medical field with a potential for leakage of personal information by compromised AIs. Also at risk is confidential and proprietary enterprise data as large language models (LLMs) become more integrated into corporate databases. “The more often a piece of information appears in a dataset, the more likely a model is to release it in response to random or specifically designed queries or prompts,” notes the report. This would include personal information like residential locations, phone numbers, and email addresses, creating security and safety concerns.
“Most of these attacks are fairly easy to mount and require minimum knowledge of the AI system and limited adversarial capabilities,” adds co-author Alina Oprea, a professor at Northeastern University. “Poisoning attacks, for example, can be mounted by controlling a few dozen training samples which would be a very small percentage of the entire training set.”
Some defense of individual modalities for AI has been used in the past, but the rise of multimodal models has similarly led to an increase in multimodal attacks. Both generative AI and predictive AI are increasingly vulnerable, according to NIST.