
Virtually every conversation you see about business in the media these days mentions some element of artificial intelligence.
According to a Reuters analysis of transcripts, the terms “AI” or “artificial intelligence” were mentioned 827 times on 76 out of 221 calls held in July of 2023. That equates to 3.7 mentions per call, more than double the 1.8 per call at the same time the previous quarter.
In response, the SEC has issued warnings about “AI Washing” to ensure their mention of AI isn’t superficial but integral to their business.
However, the big question for companies is not their public AI stance but their actions to adopt AI and generate the advantages dominating the news.
The Generative AI in the Enterprise report by O’Reilly, published in late November 2023, explores how companies use generative AI, the obstacles preventing wider adoption, and the skills gaps that must be addressed to advance these technologies.
However, the biggest inhibitor is: Where to get started. Let’s look at the landscape and dissect where and how to start.
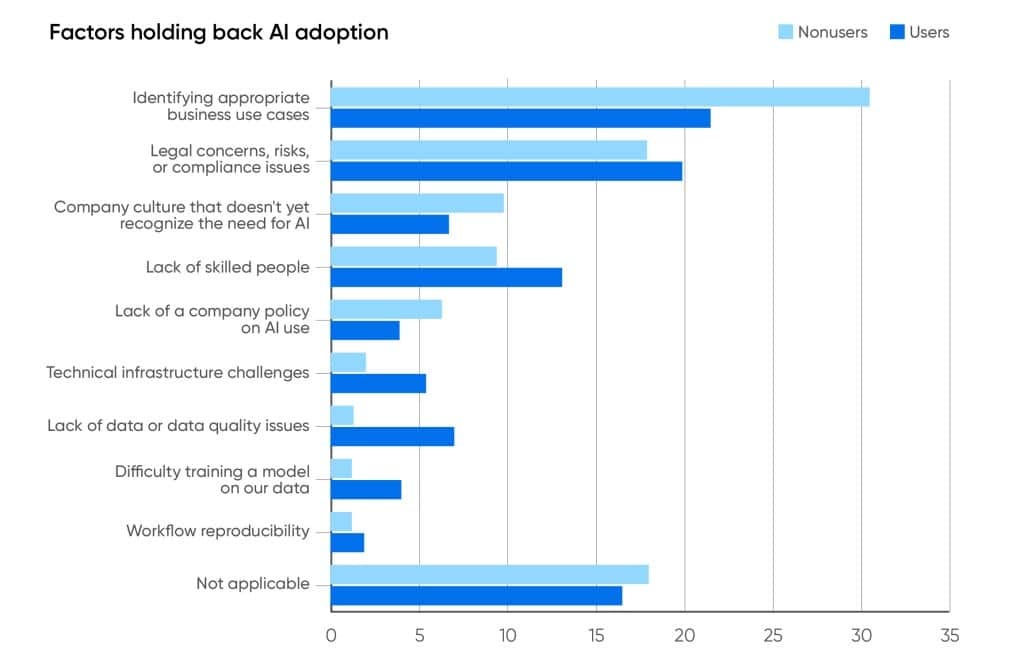
Factors Holding Back AI Adoption
The primary barrier to AI adoption and further implementation among companies is the difficulty in identifying appropriate business use cases, with concerns about legal issues, risk and compliance also playing a significant role. This challenge underscores the importance of careful consideration and understanding of the potential risks specific to AI rather than rushing to apply AI technologies without strategic thought.
Additionally, the lack of corporate policies on AI use reflects a broader uncertainty and evolving legal landscape regarding AI’s implications for copyright, security vulnerabilities, and reputational damage. Recognizing appropriate AI use cases and managing associated risks demand a thoughtful approach to integrating AI into business practices, highlighting the need for clear policies and regulatory compliance.
Top Risk for Companies Using Generative AI
The top risks companies are testing for when working with AI are unexpected outcomes, security vulnerabilities, safety issues, bias and privacy violations. Nearly half of enterprises selected unexpected outcomes as the top risk, which is concerning since incorrect results are typical with generative AI.
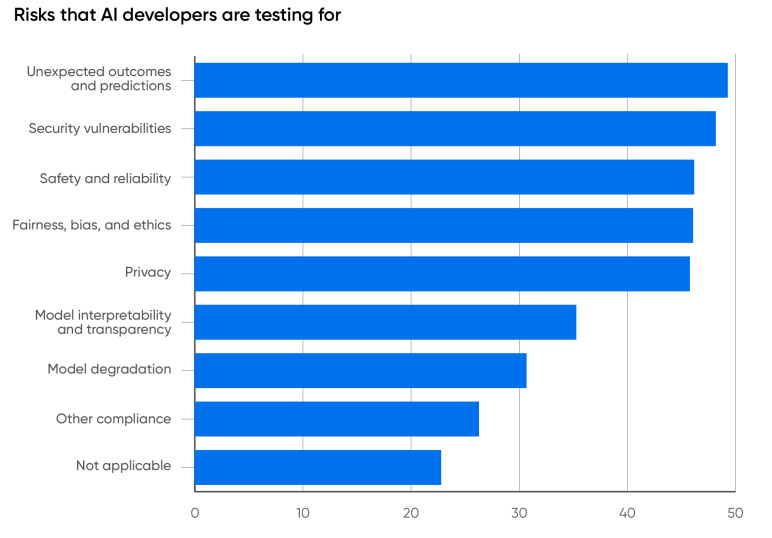
Companies should test for fairness and bias, especially in medical applications, although some applications, like building efficiency, don’t have major fairness issues. It’s positive to see safety and security ranked high, since generative AI can cause reputational and legal damages.
Model interpretability remains challenging, making diagnosing bias difficult, but it may only impact some applications. Model degradation over time is a bigger concern for developers building custom models rather than just using an existing one. Training an AI model is expensive, so model degradation that requires retraining is a substantial risk.
Companies working with generative AI must prioritize testing for unexpected outcomes, bias, safety, security and model degradation over time.
Data Privacy, A Top Inhibitor of GenAI Adoption
The data privacy landscape for AI today is marked by an intricate balance between leveraging data for innovation and safeguarding individual privacy rights amidst rapidly evolving global regulations.
Organizations are challenged to navigate complex legal frameworks and ethical considerations, ensuring their AI technologies comply with stringent data protection standards like GDPR and CCPA. As well as emerging laws like the new EU AI Act.
This environment demands rigorous data governance and privacy-by-design approaches in AI development as companies work to maintain trust and transparency with users while pushing the boundaries of technological advancement.
Utilizing anonymized and aggregated data is a common practice in AI applications aimed at safeguarding individual privacy while harnessing valuable insights. Despite these efforts, risks persist.
Anonymization techniques are not foolproof; sophisticated algorithms can re-identify individuals from seemingly innocuous datasets. As highlighted in a comprehensive analysis by McMillan LLP, the illusion of anonymity can quickly dissipate, exposing organizations to legal, reputational and financial peril.
Key Takeaways:
- Rigorous Privacy Measures: Implementing robust data governance policies and adopting state-of-the-art anonymization techniques are non-negotiable to protect sensitive information.
- Regulatory Compliance: Staying abreast of evolving data protection laws ensures that your AI initiatives remain within legal bounds, safeguarding against potential litigation.
- Ethical Considerations: Beyond compliance, ethical data stewardship reinforces trust among users and stakeholders, cementing the foundation of your AI-driven endeavors.
New Privacy-Preserving Methods
Organizations need privacy-preserving AI solutions to securely leverage large language models (LLMs) like GPT-3 on confidential enterprise data. Existing techniques like homomorphic encryption, secure multi-party computation, and differential privacy have significant functionality, computational efficiency, or data protection limitations for generative AI workloads. However, an emerging approach called confidential computing shows promise by isolating data in hardware-based trusted execution environments (TEEs) during processing.
TEEs such as Intel SGX enclaves or AMD SEV virtual machines allow remote attestation to establish trust, encrypt data in memory to prevent unauthorized access, and efficiently decrypt data for computation. As an open industry standard focused on data security during computing, confidential computing is crucial for multi-party analytics, privacy compliance, and data sovereignty. Its isolation and encryption capabilities make it well-suited to enable privacy-preserving generative AI without sacrificing model performance.
In summary, whether based on confidential computing hardware or advanced cryptographic methods, privacy-enhancing technologies are critical for organizations to harness the full potential of large language models on sensitive data with appropriate security controls. The latest techniques can address gaps left by previous privacy approaches to unlock secure and performant generative AI.
Choosing the Right AI Models: The Open Source Imperative
While GPT models grab the most headlines, the landscape of AI models available for building applications is expanding at a staggering rate. Scarcely a day passes without announcing a new model, and a glimpse at Hugging Face’s model repository reveals over 500,000 options to choose from – a hundred thousand more than just three months prior.
Developers are spoiled for choice like never before. But amidst this Cambrian explosion of models, which ones are developers putting to use? Past the breathless announcements and bursts of hype, where are development attention and effort focused?
Getting concrete data on real-world model adoption and use cases is key to cutting through the noise and understanding these innovations’ true impact. As the models proliferate, tracking how they make their way into applications will shed light on the ones delivering tangible value.
The selection between leveraging public AI models and developing proprietary ones carries strategic implications for enterprise applications. Public models, while readily accessible, may not cater to the unique needs or proprietary nuances of your business. Conversely, building a private model requires significant resources, from data collection to training and maintenance.
Recently, I discussed the critical role of open source AI models in this context, which cannot be overstated. But not every enterprise has the resources to deploy its own model. Using selection criteria that best meet your enterprise’s needs is essential.
Considerations for Selecting LLMs for Your Enterprise
- Strategic Alignment: Assess whether a public, proprietary, or open source model aligns with your strategic objectives, considering factors such as the need for customization, control over data, and competitive differentiation.
- Performance and Scalability: Leverage resources like Hugging Face’s Leaderboard to evaluate model performance against relevant benchmarks and scalability to meet your application needs.
- Customization and Flexibility: Open-source models offer significant advantages in terms of customization, allowing enterprises to tailor solutions to their specific needs while benefiting from community-driven enhancements.
- Transparency and Trust: The open nature of these models provides transparency, addressing security vulnerabilities and ethical concerns, which is crucial for enterprise applications.
- Cost and Resource Implications: Building a proprietary model involves substantial investment in data collection, training, and maintenance, whereas leveraging open-source models can be more cost-effective and resource-efficient.
- Community Support and Collaboration: Open-source models offer access to a vast community of developers and experts, facilitating faster problem-solving, innovation, and collaborative improvement.
- Regulatory Compliance and Data Privacy: Consider models that align with regulatory requirements and data privacy standards relevant to your industry and operational geography.
- Long-term Viability and Support: Evaluate the model’s roadmap and the provider or community’s commitment to ongoing support and development to ensure long-term viability.
Key Takeaways:
- Flexibility and Innovation: Open source AI models provide the flexibility to tailor solutions to specific enterprise needs while benefiting from community-driven enhancements.
- Transparency and Trust: The transparency inherent in open source models is crucial for security and ethical considerations.
- Community Support: Access to a broad community accelerates development cycles and fosters innovation through collaborative problem-solving.
Choosing the right LLM requires a balanced consideration of strategic goals, performance requirements, cost implications, and the broader ecosystem’s support. Open source models, in particular, offer a compelling mix of flexibility, transparency, and community support that can significantly benefit enterprise applications.
Conclusion: Embracing AI for Unparalleled Technological Advancement
Incorporating AI into enterprise applications is poised to offer our era’s greatest technological leap forward. The path, however, is lined with critical decisions that will define the trajectory of success. Prioritizing data privacy is a legal obligation and a fundamental component of building trust and integrity in AI applications.
Simultaneously, the choice of AI models—especially the commitment to truly open source options—reflects a strategic investment in your AI initiatives’ sustainability, innovation, and inclusivity.
As we stand on the brink of this AI revolution, making informed, ethical and strategic choices is paramount. The promise of AI is immense, but its potential will only be fully realized through thoughtful consideration of these key aspects today to avert pitfalls and unlock true value tomorrow.
(This article was originally featured in The Artificially Intelligent Enterprise (TheAIE) Newsletter. The AIE is the official newsletter and co-producer of the world’s biggest free artificial intelligence conference for enterprise users. TechStong is the co-producer and media partner of this event being held on May 21st, 2024. To get your free ticket to this must-attend event featuring executives, developers and business leaders sharing their strategies on how to succeed with AI, register HERE today.)