

At the AI Infrastructure Field Day in April, I spent a full day immersed in Google Cloud’s vision and capabilities for powering the next wave of artificial intelligence (AI). From purpose-built hardware like Google’s own TPUs and NVIDIA GPUs to sophisticated storage solutions and networking fabrics, Google presented a comprehensive picture of its AI Hypercomputer – an integrated solution designed to tackle the entire AI lifecycle.
In simple business terms, the AI Hypercomputer platform provides an integrated stack encompassing hardware, software and networking that run together like clockwork. The approach avoids costly integration problems and performance bottlenecks often encountered when mixing components, ultimately reducing wasted resources and accelerating time-to-market for AI projects.
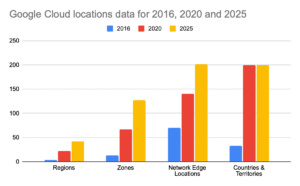
As a delegate attending the session, I was curious about the rate of expansion for Google Cloud and visited The Wayback Machine to look up the history of Google Cloud locations over the years. Cherry-picking my date, I noted that the pace of growth for Google Cloud is quite remarkable when viewed over roughly 10 years from 2016 to 2020 to 2025.
Storage, but Automated and Intelligent
For most businesses, managing massive datasets presents significant operational challenges and hidden costs. Google’s Storage Intelligence platform that is part of the AI Hypercomputer stack simplifies this with a unified management, freeing up valuable engineering resources spent on building complex custom tools. The simplification cuts operational costs while improving data governance and reducing security and compliance risks through features like metadata analysis and the timely inclusion of robust public access checks. Nevertheless, acting on the object post-exposure means retroactively traveling through time to correct prior realities in the multiverse — but still a cool way to call out the default internet accessible object storage trope.
As for whether there is any kind of policy as code where Google’s Storage Intelligence platform can present a geopolitical overlay to ensure data governance but without data sovereignty concerns and a shared responsibility, the short answer is yes. Since Google Cloud offers custom org policies to restrict data movement to specific regions (e.g., only U.S. regions), automated enforcement at the account level is currently possible — but is very clearly a shared responsibility. More granular, dynamic policy integration directly in the storage management tool is not yet available, but base capabilities exist within a shared responsibility model.
Google Cloud stated that it is technically possible to merge on-premises metadata with Google Cloud’s Storage Intelligence for unified analytics (via BigQuery), but cautioned that on-premises metadata is not a first-class product feature yet and that the user would need to be responsible for harvesting and merging metadata externally. While focus is currently on cloud storage, there will be plans to expand the solution’s hybrid capabilities.
Simplified and Faster
To make Google Cloud Storage (GCS) performant for demanding AI tasks, Cloud Storage FUSE enhancements accelerate critical steps like data loading and checkpointing directly on cost-effective object storage, avoiding complex data migrations. Complementing this, Anywhere Cache provides an easy, transparent zonal SSD cache, further boosting read speeds, simplifying infrastructure and lowering data access latency for faster AI results.
For workloads demanding even lower latency, particularly during intense training or checkpointing phases, Managed Lustre offers a high-speed managed parallel file system. This simplifies migration from specialized on-prem systems and maximizes GPU/TPU throughput without the internal complexity of managing Lustre, leveraging its proven architecture optimized for concurrent access and efficient metadata handling.
Blurring the lines further, the new Rapid Storage (currently in preview) combines cloud storage scalability with near-instant zonal access speeds by exposing Google’s internal Colossus file system via Google Storage FUSE and Hierarchical Namespace (HNS). Rapid Storage offers a powerful option for latency-sensitive applications and potentially simplifying architectures.
Data, but Streamlined and Flexible
Effective data preparation is foundational to AI success. Google optimizes GCS for analytics tools (like Spark), often used in this critical stage, and supports modern Data Lakehouse architectures using open standards like Apache Iceberg. This unified approach streamlines data prep and allows both AI and business intelligence teams to securely work on the same governed data without costly duplication, improving efficiency and offering flexibility in tooling.
Computation, Orchestrated
Of course, bringing computation to data is key. Deploying the compute environments for these tasks is simplified by Cluster Toolkit, which accelerates the setup of optimized AI and high performance computing (HPC) clusters from months to minutes. Using simple ‘Blueprint’ templates ensures best practices and performance optimization (like VM placement via Cluster Director) from the start, lowering the barrier to entry without hidden costs.
Orchestrating larger-scale workloads reliably falls to Google Kubernetes Engine (GKE), which is enhanced for massive scale (up to 65k nodes) and performance within the AI Hypercomputer using standard Kubernetes interfaces but with unique Google Cloud topology awareness. The aim is to reduce operational burden, ensure smooth scaling for large models and maximize expensive hardware utilization.
One question I and other delegates had was how the concise cluster blueprints (e.g., 62 lines) generated by extensive Terraform code (e.g., 40,000 lines) would be groomed and updated over the lifecycle of projects. Behind the question is an acknowledgement of the challenges from operational configuration drift when writing in any domain specific language (DSL). Google clarified that it focuses audits on the human-readable blueprint, as it deterministically generates the full Terraform code and argued that compliance and restrictions can be enforced effectively at this higher blueprint/UI level. The choice of using a domain-specific language (YAML) for blueprints was discussed, with the acknowledgment that while it’s the current method, the goal is to simplify cluster creation further, potentially exploring UI-driven or natural language interfaces in the future.
Google addressed the recent changes in Terraform’s licensing and confirmed it is evaluating alternatives, including leveraging its own APIs and other open-source options like OpenTofu.
Custom, Popular Silicon
Powering these clusters, Google Cloud provides rapid access to the latest NVIDIA GPUs, delivering significant performance leaps (~2x gen over gen) crucial for faster training. The A4 VM (B200) was highlighted for strong price-to-performance, though Google acknowledged that practical adoption balances speed with hardware availability and migration costs — as well as the clear requirement for enabling customer choice.
Google Cloud also offers its own custom silicon – Trillium Tensor Processing Unit (TPU) – providing a powerful, efficient alternative optimized for AI scale, leveraging deep hardware-software co-design (meaning that customer and Google Cloud work hand in hand to make ongoing improvements).
The upcoming Ironwood (TPU v7 and v7x) promises massive scale, potentially lowering training costs and time for workloads optimized for Google’s ecosystem — at a comparable 29x power improvement over prior TPU generations, Google Cloud said. All this with a 12-18 month iteration on the TPU’s roadmap in addition to flexible consumption models for 1, 2 and 3 year models demonstrate a commitment to vertical integration within the Google Cloud infrastructure value chain.
The footprint and demand discussion section of the talk provided a window into how capacity planning and product engineering balance the budgets for deterministic power, weight, cooling and geometry. Based on the story shared, Ironwood generations may provide Google with long-term planning advantages within existing facilities, PPAs, vPPAs and related so-called green initiatives.
Clearly, demand is growing for data center capacity as well as the energizing and cooling of these unique facilities. Perhaps, Ironwood and product management-driven incentive pricing models will make it possible for Google Cloud to simultaneously increase customer AI workload capacity within existing data center footprint, while simultaneously increasing operational efficiency through the aforementioned orchestration becoming, itself, AI-powered.
Turnkey and Automated Networking
Connecting these distributed resources and users requires robust networking. Cloud WAN simplifies complex corporate networks using Google’s reliable global backbone for diverse connectivity needs.
The introduction of Cross-Site Interconnect adds managed Layer 2 site-to-site capabilities, reducing reliance on multiple providers and legacy MPLS, potentially cutting TCO and improving reliability. If VPN equals Vexing Productivity Neutralizer, then Google – the company that brought a BeyondCorp approach to access – is moving the industry forward once again.
Specific network optimizations further enhance AI, particularly with the GKE Inference Gateway. This focus on simplification and optimizations of networking for customers makes AI serving faster, cheaper, and more secure via intelligent load balancing (KV Cache-aware), metric-based auto-scaling, multi-model density support and integrated AI security tools.
Effectively, Google Cloud is improving the end-user experience while also centralizing security management and removing more of the error-prone human elements that traditionally have contributed to deleterious impacts from fat fingering within manual processes.
AI Infrastructure that is Uniquely Google
Overall, Google Cloud presented a compelling, deeply-integrated vision for AI infrastructure, emphasizing performance, scale, efficiency and increasingly simplified management across compute, storage and networking. The presentations showcased a mature, comprehensive and rapidly evolving, vertically integrated AI platform that is designed not just to provide raw power, but to solve the practical challenges businesses face in deploying and managing AI effectively and efficiently at scale.