
Introduction
As organizations deploy increasingly sophisticated AI systems, the conversation often focuses on larger models and more powerful GPUs. However, AI inference is rapidly exposing a different challenge: managing the growing amount of context required to generate useful responses. During presentations at AI Field Day, Solidigm explored how prompt construction, memory hierarchies, storage architectures, and capacity planning are becoming critical components of AI infrastructure. The sessions highlighted a change in thinking from AI as a compute problem toward AI as a context and memory problem.
Industry Background
The AI industry has spent the last several years focused on scaling model size and compute capacity. New generations of GPUs, larger foundation models, and specialized accelerators have enabled dramatic advances in AI capabilities. At the same time, organizations are increasingly deploying agentic workflows, retrieval-augmented generation (RAG), and long-running conversational systems that depend on retaining large amounts of context.
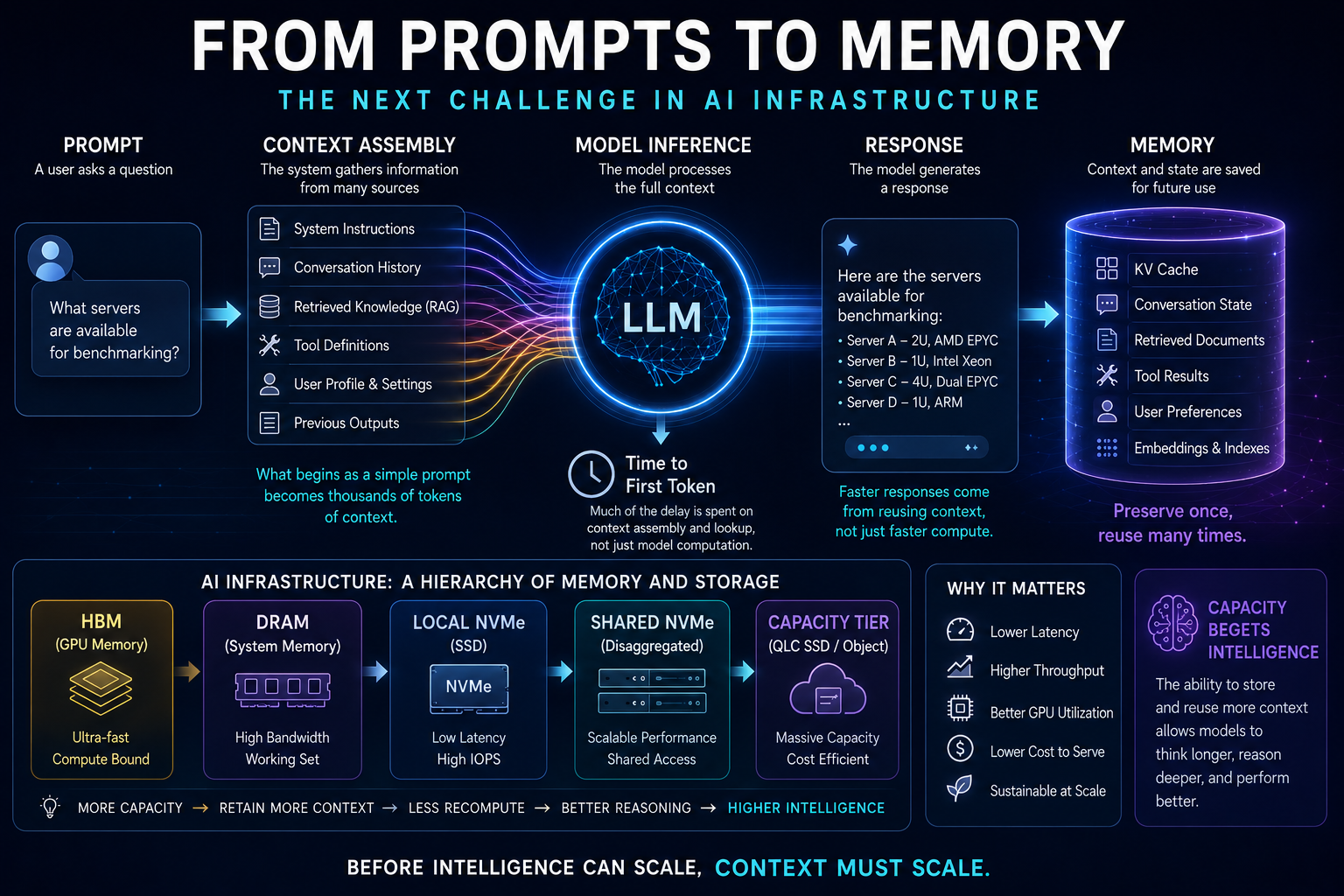
These workloads introduce challenges that differ from traditional AI training environments. Modern inference systems must repeatedly assemble context from system instructions, organizational knowledge bases, tool definitions, previous interactions, and retrieval systems. What begins as a simple user prompt often expands into thousands of tokens before processing even begins.
As context windows grow and agentic systems become more common, organizations must think beyond raw compute performance. The ability to efficiently store, retrieve, and reuse context is becoming a critical factor in AI responsiveness, scalability, and operational efficiency.
One of the most interesting discussions during the session emerged from a seemingly simple question about caching. If multiple users ask the same question, should an AI system reuse previously computed results? The answer turned out to be far more complicated than expected. Differences in session state, security boundaries, conversation history, and model behavior mean that identical questions are not always identical at the infrastructure level. The discussion quickly evolved from storage architecture to semantic architecture, raising a broader question about whether future AI systems will require dedicated layers responsible for recognizing meaning, similarity, and shared context before requests ever reach a model. In many ways, this may be the next stage of AI infrastructure evolution—not simply storing information, but understanding when information has already been learned.
This distinction becomes increasingly important as organizations adopt agentic AI systems. Agents revisit prior information, maintain state across multiple interactions, invoke tools, and build on previous reasoning. Each interaction increases the value of preserving context rather than reconstructing it from scratch.
Company and Technology
At AI Field Day, Solidigm explored this challenge through a presentation called “The Anatomy of a Prompt.” Senior Principal Engineer Kapil Karkra demonstrated how AI systems build context before inference occurs and highlighted the significant amplification that takes place between a user’s original prompt and the final prompt processed by the model.
The presentation focused on the concept of time to first token, a key inference metric that measures how long it takes before a model begins generating a response. Solidigm argued that much of this delay comes from assembling and processing context rather than generating output. By retaining previously computed state through techniques such as retrieval systems and KV cache offload, organizations can reduce repeated computation and improve overall efficiency.
A central theme throughout the discussion was that AI systems increasingly spend time reconstructing what they already know. As context windows expand through conversation history, retrieval operations, tool calls, and memory lookups, the cost of repeatedly rebuilding that state becomes increasingly significant.
This perspective positions storage as more than a repository for data. Instead, storage becomes an active participant in AI inference, helping preserve context that would otherwise need to be recomputed by expensive GPU resources.
Product Specifics
Solidigm expanded this discussion by examining how storage architectures are evolving to support AI workloads. The company described a hierarchy of memory and storage tiers spanning high-bandwidth memory, DRAM, local NVMe storage, shared NVMe infrastructure, and large-scale capacity tiers. Each layer plays a role in supporting retrieval workloads, KV cache storage, and long-context inference.
A second presentation, “Capacity Begets Intelligence,” connected these infrastructure decisions to AI performance. Using a framework called CRAFT—Comprehension, Recall, Adaptability, Fluency, and Tenacity—Solidigm argued that capacity can directly influence AI behavior. The premise was that systems capable of retaining and reusing larger amounts of state allow models to spend less time recomputing information and more time reasoning.
One of the more compelling examples involved reasoning models solving difficult mathematical problems. When the model’s reasoning process was truncated because capacity limits were reached, performance suffered dramatically. When sufficient capacity was available to allow the reasoning process to continue, benchmark scores improved significantly. The implication was striking: intelligence may not be solely a property of the model itself, but also of the infrastructure that supports it.
The company also discussed practical considerations including liquid-cooled storage platforms, disaggregated storage architectures, power efficiency, sustainability initiatives, and the role of NVMe technologies in supporting large-scale inference environments. Throughout the sessions, the central theme remained consistent: storage is becoming a day-zero architectural decision for AI infrastructure rather than a component added later in the design process.
Conclusion
The rapid growth of agentic AI, retrieval systems, and long-context reasoning is creating new demands on infrastructure. While compute remains essential, AI performance increasingly depends on an organization’s ability to manage, preserve, and retrieve context efficiently. Solidigm’s presentations highlighted how storage technologies can contribute directly to inference performance by reducing recomputation, supporting cache reuse, and enabling larger working sets for AI workloads.
My primary takeaway from the sessions was not that storage is replacing compute as the central challenge in AI infrastructure. Rather, the industry is beginning to recognize that context itself has become an architectural concern. As AI systems evolve from simple prompts to long-running agents with persistent memory, the ability to retain and reuse context may prove just as important as the ability to generate it.
For organizations evaluating AI infrastructure strategies, the key takeaway is that context has become a first-class architectural concern. Before intelligence can scale, context must scale as well. To learn more about Solidigm’s approach to AI infrastructure, storage architectures, and inference optimization, visit Solidigm and explore the technical resources and demonstrations discussed during AI Field Day.