
Jedify today revealed it has raised another $24 million to advance the development of a platform that enables organizations to build their own context graph that connects to any artificial intelligence (AI) model of their choosing.
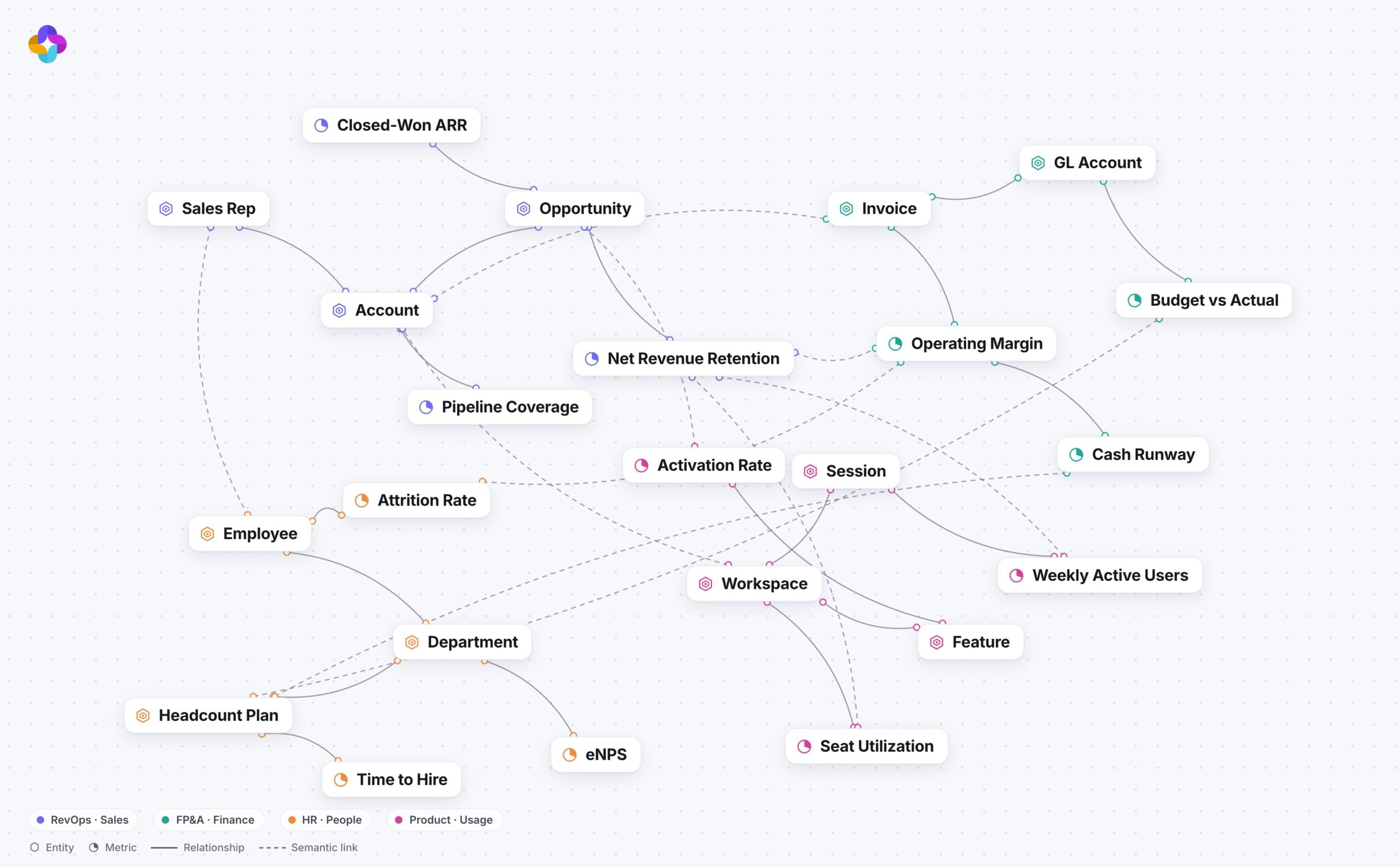
The Jedify platform is based on a knowledge graph, dubbed Semantic Fusion, that was created specifically for AI agents, says Jedify CEO Assaf Henkin. That core technology allows organizations to generate their own custom graph to provide AI agents with the context they require to efficiently and accurately automate a task, he adds.
Just as importantly, the knowledge graph also reduces the total number of tokens that need to be consumed because the AI agent can spend less time reasoning across data that provides the context it needs to perform a task, notes Henkin.
There are fundamentally two challenges large organizations are encountering as they try to operationalize AI agents. The first is the simple fact that enterprise data is typically strewn across multiple applications and platforms. An AI agent on its own is not able to determine, for example, which definition of revenue to use or which customer record is more current than another. A knowledge graph captures metric definitions, entity relationships, lineage, permissions, business rules, operational assumptions and domain-specific terminology in a way that makes it simpler for an AI agent to efficiently navigate enterprise data. “That semantic data gets included in the prompt,” says Henkin.
The second major challenge is that, in the absence of any way to efficiently navigate data, the total cost of deploying AI agents quickly becomes prohibitive as the number of tokens being consumed escalates. A knowledge graph greatly reduces the number of tokens that need to be consumed by not relying on the AI model to reason across massive amounts of data to generate context that is now instead readily available via a context graph.
Every interaction with an AI agent ultimately serves to make the context graph richer, which in turn benefits the next AI agent that invokes it, notes Henkin.
Each organization will need to determine how best to deploy AI agents and enforce guardrails and policies, but the one thing that is apparent is that unless long-standing issues pertaining to how data is actually managed are addressed, it will be difficult to justify the return on investment (ROI) in AI agents. In fact, if AI agents keep generating flawed outputs those investments may wind up even being counterproductive.
There are, of course, multiple ways to provide AI agents with the context they require to safely and accurately perform a task. The challenge is there tends to be a lot more focus on the AI agents themselves versus the backend data sources on which they depend. The simple truth is that the investments that need to be made to make those data sources available in a way an AI agent can readily consume are not always initially factored into the budgets allocated to an AI project.
Hopefully, however, as organizations gain more hard-won experience with AI agents, they will realize how dependent they are on platforms that need to be deployed outside of the AI model itself.