
DataHub today extended its context engineering platform to ingest metadata in real time to ensure artificial intelligence (AI) agents and applications have access to the latest, most accurate data available.
Version 1 of the DataHub Cloud creates an independent context layer between AI agents and the data they are accessing to ensure consistency across the outputs generated, says DataHub CTO Shirshanka Das.
At the core of that capability is a data graph that collects and correlates metadata from more than 100 external sources, such as a data warehouse, to make sure AI agents are accessing validated data. The semantic meaning is derived from query histories that are continuously updated and from definitions that have been previously validated.
When an agent is prompted, it retrieves not just schema but validated query patterns that have answered similar questions before, complete with proven joins, filters and aggregation logic. The end result is a knowledge base for AI agents through which every change is timestamped and versioned in a way that can be easily audited, notes Das.
DataHub also provides access to a ContextHub through which domain experts can create workspaces to review, approve and enrich AI-proposed context, collaborate with colleagues and simulate the impact of context changes on text-to-SQL results.
There is also a Context Activation capability that allows any agent or workflow to invoke DataHub context as a set of prebuilt skills, and an enhanced Agent Context Kit to access software development kits (SDKs) and application programming interfaces (APIs).
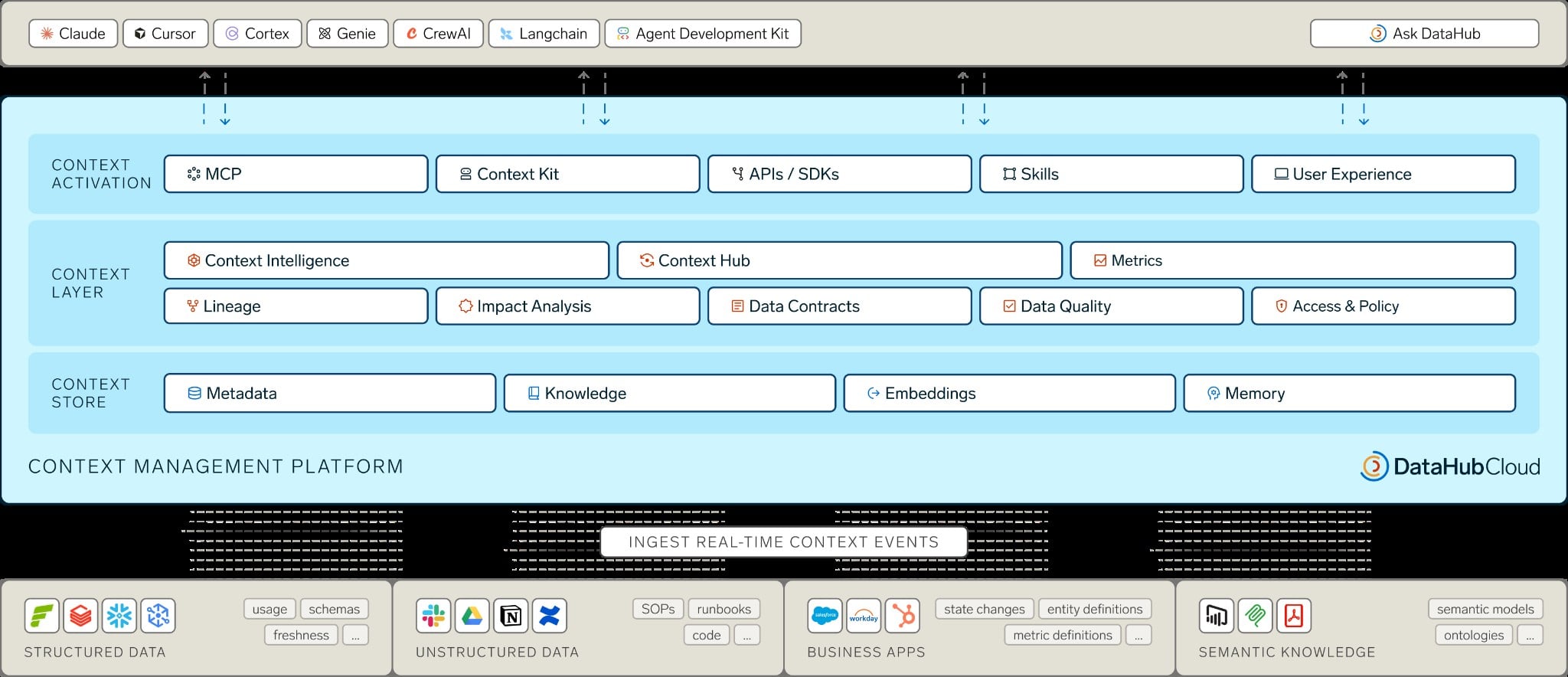
Fundamentally, DataHub is making a case for a context engineering platform that makes it possible to centrally manage what data is exposed to an AI agent. “We believe context engineering needs to be provided via shared infrastructure,” says Das.
Otherwise, different AI agents are exposed to data sets that are likely to have been inconsistently updated, resulting in unreliable outputs that organizations are not able to reliably act on, adds Das.
The overall goal is to ensure that AI agents have access to a trusted source of complete data that ensures the outcomes generated are as deterministic as possible, he adds. Otherwise, an AI agent will simply make a guess to fill in any gaps that might exist, says Das.
With the rise of AI agents, organizations now need to address fragmented data management systems that in some cases have been in place for decades. Requiring AI agents to organize that data each time they perform a task results in high levels of token consumption that is already proving to be unsustainable. The missing piece is an external platform that provides AI agents with the context they need to more accurately generate outputs at lower total cost.
It’s not clear yet how rapidly organizations are revamping the way they manage data in the age of AI, but a recent Futurum Group report projects the global data intelligence, analytics, and infrastructure (DIAI) market is projected to grow at a 17% compound annual growth rate through 2028 off a base of $541.1 billion in 2026.
The challenge, of course, is determining how best to allocate those budget resources in a way that creates AI outputs that organizations can bet the business on.