
RapidFire AI has made available a rapid experimentation engine to fine tune and post tune large language models (LLMs) under an open source license.
Company CEO Jack Norris said that the overall goal is to make a tool for distilling small language models using foundational models in a way that also reduces hallucinations more accessible to a wider range of organizations.
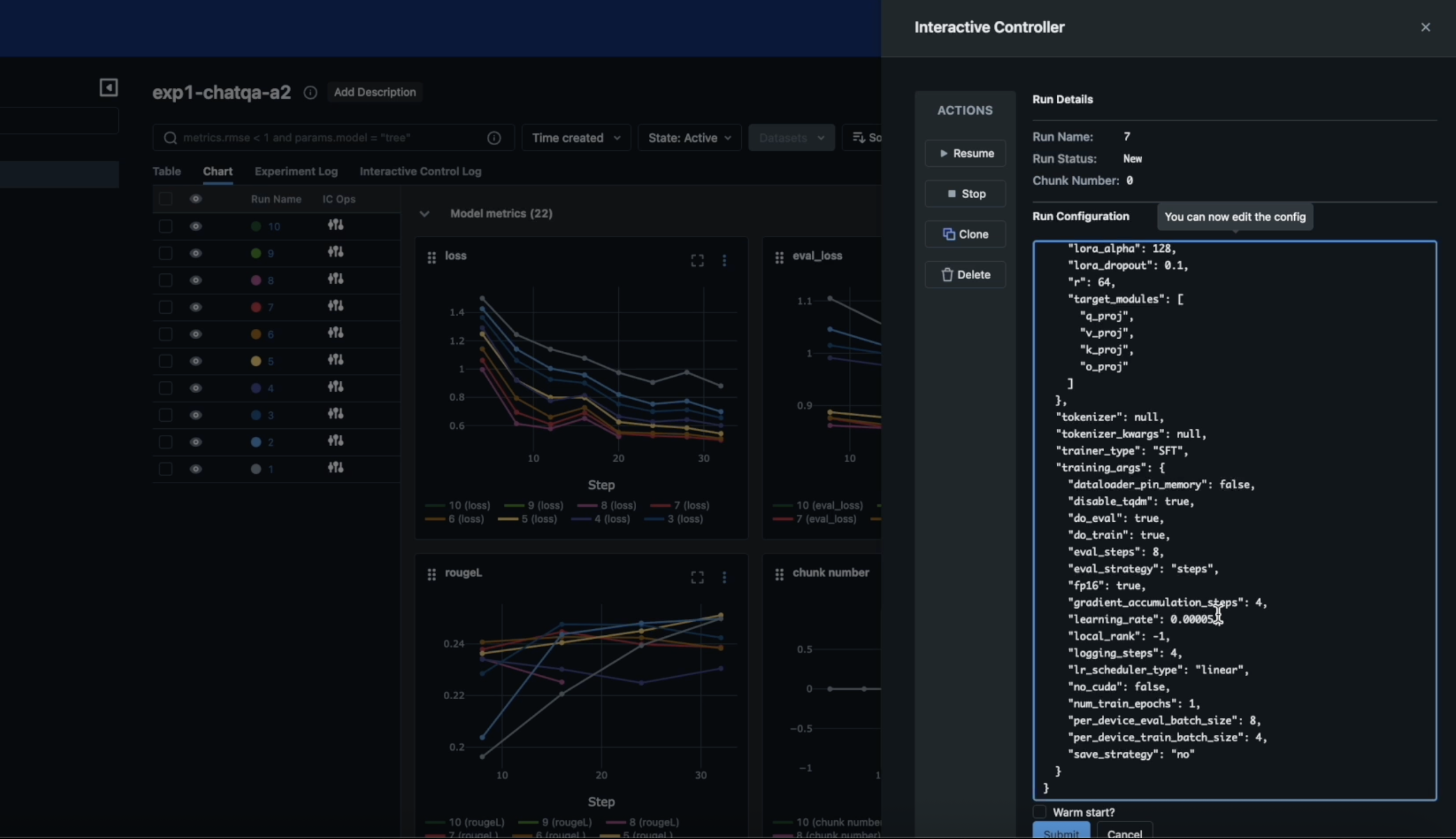
The RapidFire AI platform is specifically designed to enable data scientists to launch and compare multiple fine-tuning/post-training configurations running in parallel on a single graphics processing unit (GPU) or across multiple GPUs that span data, model/adapter choices, trainer hyperparameters, and reward functions. It does this by training on dataset chunks and then swapping adapters or base models between chunks, while a scheduler automatically reallocates GPUs to improve overall utilization.
Live metrics then stream to an MLflow dashboard that enables a data science team to stop, resume, and clone-modify configurations in a way that makes it simpler to both prevent weak configurations from running in the first place while warm‑start new configurations for better performing models in real time right from the RapidFire AI dashboard.
Designed to be compatible with tools such as PyTorch, the RapidFire AI tool essentially unifies the tracking and visualization for all metrics and metadata management via a single control panel.
Very few organizations are going to build foundational models so the goal needs to be to make it simpler for organizations to extend the efforts of others to create smaller AI models that are trained to automate a specific set of tasks, says Norris. The challenge is there is a clear need to automate what today are a series of sequential steps that are making it difficult to experiment with multiple AI models at the same time, he adds.
By automating the process of training an AI, it becomes more feasible for organizations that lack a lot of expertise to build and deploy AI models, notes Norris. “Right now, there are just so many knobs to turn,” he says.
It’s not clear how many organizations are building small language models, but as more of them embrace AI agents to automate tasks, the need for small language models that have been trained using a validated set of data that ensures higher quality outputs will steadily increase, adds Norris.
Achieving that goal, however, isn’t going to be feasible unless the underlying plumbing issues involving the training of AI models becomes more automated, he notes.
It might be a while yet before AI agents and the small language models that drive them are pervasively deployed across an enterprise, but the need to experiment with them is becoming a lot more pressing as organizations realize the degree to which many manual tasks might soon be automated. The challenge, as always, is there is a limited pool of data scientists available, which means if organizations are ever going to create a truly agentic enterprise they will need to find ways to make data science teams fundamentally more efficient.